- GenAI360 - Weekly AI News
- Posts
- PyTorch LLM Improvements, Oracle & Salesforce Conference Updates, Google’s 🐳 AI
PyTorch LLM Improvements, Oracle & Salesforce Conference Updates, Google’s 🐳 AI
Plus, Mistral Debuts Pixtral 12B Multimodal Model
But seriously, when did we start naming stuff after fruit instead of animals? Looking at you, 🍐 (oof) and the non-profit that decided to morph into a for-profit entity, with the last founding member deciding to depart faster than you can say "I have no equity in OpenAI… I do this because I love it, 💚 ". Anyways, this week is full of news (and there have been many more over the weekend), so let's dive right in! But first:
GenAI360 Exclusive: Unlock Free Tickets for RetrieveX Conference on Oct 17 in San Francisco.
Come hear from the creators of Meta Llama, PyTorch, Kubeflow, CAFFE, along with leaders from Microsoft, AWS, Bayer, Flagship Pioneering, Cresta, VoyageAI, Omneky how to build best retrieval for AI.
If you're executive who's considering or working on GenAI projects, fill in the form below for a complimentary ticket for the conference - hurry up because tickets are limited!
Date: October 17, 10:30am - 7pm PT
Venue: The Midway, 900 Marin St, San Francisco
Key Takeaways
Mistral released Pixtral 12B, their first multimodal model capable of processing both images and text, outperforming other top models on various benchmarks.
IBM researchers presented improvements to PyTorch, including a high-throughput data loader and enhanced LLM training throughput.
Google developed a whale bioacoustics model capable of identifying eight distinct whale species and multiple vocalizations.
General OCR Theory employs a unified end-to-end model with a high-compression encoder and long-context decoder, which outperformed existing models on various OCR tasks.
OpenAI's o1 model shows significant improvements over GPT-4 on reasoning-heavy tasks, rivaling human expert performance on many benchmarks.
A paper drawing parallels to quantum mechanics applies the Universal Approximation Theorem to explain LLM memory mechanisms, and found some models able to memorize nearly 100% of 2,000 poems after limited exposure.
Got forwarded this newsletter? Subscribe below👇
The Latest AI News
We’ve been hearing about Project Strawberry for a while and it’s finally here, with OpenAI releasing a preview version of the model called o1. There were a bunch of other releases too, including multimodal modals, speech-text foundation models, and open-source development frameworks.
Some interesting models for life science applications also came up, which might have gone under the radar amidst the o1 release hype.
Mistral Enters Multimodal Arena and Groq’s New Release
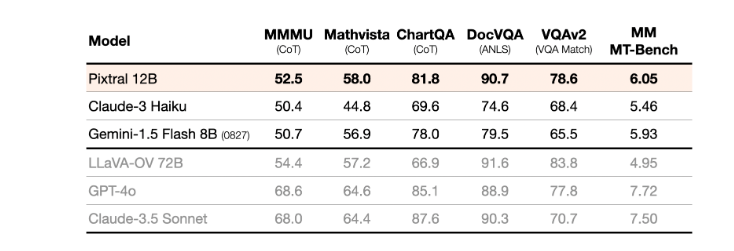
Mistral’s first multimodal model showed promising results on various multimodal benchmarks. (Source)
Pixtral 12B is a new multimodal AI model from Mistral, who previously released three models at around the same time. This new model is capable of processing both images and text. It has 12 billion parameters and is approximately 24GB in size.
Built on Mistral's Nemo 12B text model, it can answer questions about multiple images of any size using URLs or base64-encoded images.The model is expected to perform tasks like image captioning and object counting, similar to other multimodal models like Claude and GPT-4o.
Pixtral 12B also performed well on various multimodal benchmarks like MMMU and ChartQA, outperforming other top models like Claude 3 Haiku and Phi-3 Vision.
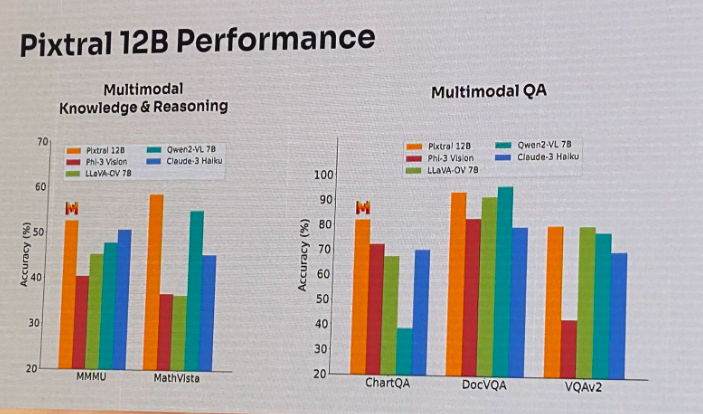
Don't hate us for this shot. Pixtral 12B’s results on various multimodal benchmarks. (Source)
Instead of another multimodal model release, we saw an open-source development framework pop up. xRx by Groq lets developers make conversational AI solutions by combining multimodal input and outputs.
It makes life easier for users wanting to develop projects like voice-based assistants, text-based chatbots, and multimodal applications by giving them all the tools they need in one place.
Oracle’s Multicloud Vision and Tensor Parallelism Breakthroughs
The conference season is upon us (while we're at it - grab your tickets for RetrieveX). PyTorch Conference, Dreamforce, the Oracle CloudWorld…
Speaking of the latter, Oracle's CTO Larry Ellison announced a new partnership with AWS, following similar deals with Microsoft and Google. The partnership, called Oracle Database@AWS, will embed Oracle Cloud Infrastructure inside AWS data centers. They've also annouced APEX, a low-code development platform, uses AI to help create secure applications from the start.
What’s more is that Ellison mentioned that Oracle is already building a >1GW data center that’s powered by 3 data centers, and that Oracle is probably going to have 2000 data centers worldwide.
The PyTorch conference also took place at around the same time. Previously, we saw the release of a PyTorch API.
Developments are continuing as we saw the implementation of experimental async tensor parallelism support, integrated into TorchTitan. It can be used with torch.compile, which automatically detects TP patterns and rewrites them into async-TP ops, or directly in eager mode by calling async-TP ops.
There were a couple of key performance challenges tackled by this implementation, including communication overhead and magnified wave quantization inefficiencies. As such, addressing these issues helped maintain real-time performance while incorporating complex learning mechanisms.
Some notable results include:
In Llama3 7B, async-TP achieved up to ~29% forward pass speedup and ~8% E2E speedup.
For Llama3 70B, it showed up to ~20% forward pass speedup and ~8% E2E speedup.
Project Strawberry Benchmarks: 'AGI Wen?'
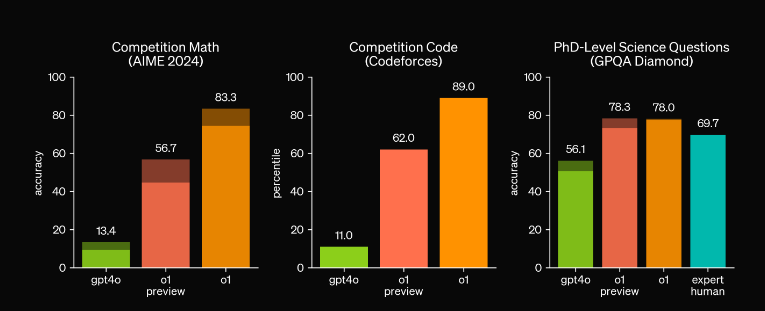
OpenAI’s latest model shows drastic improvements in competitive benchmarks over GPT-4. (Source)
After all the build up, OpenAI finally made an official announcement about Project Strawberry. It’s actually called “OpenAI o1” instead.
In the past, they used a combination of supervised and reinforcement learning for models like GPT-4. This time, OpenAI took a slightly different approach to training their latest model, using a large-scale reinforcement learning algorithm to teach the model productive thinking. The model’s performance consistently improves with more reinforcement learning (train-time compute) and more time spent thinking (test-time compute).
In terms of results, it seems like OpenAI o1 lives up to the hype by significantly outperforming GPT-4o on most reasoning-heavy tasks. It also shows major improvements on challenging benchmarks like AIME (math), Codeforces (programming), and GPQA Diamond (PhD-level science questions), exceeding human expert performance on reasoning-heavy tasks. We've yet to see nice results in production (beyond… Devin's reference), but we are currently using and liking it, too.
Currently, o1-preview is being released for immediate use in ChatGPT and to trusted API users. OpenAI is also A/B testing a feature where model selector is disabled, opening up speculations they're working on model router to mange inference costs on consumer plans (and serving a ‘good enough' model).
Since PhD-level intelligence was a hot topic during the whole speculation phase of o1, it was interesting to see how it stacks up against other models on ARC Prize.
Salesforce, Microsoft, and Amazon’s New Releases
After releasing a couple of autonomous AI agents, Salesforce also released Agentforce (confidently priced at $2 per conversation, ugh), which offers various pre-built AI agents for specific business functions, including Service Agents, SDRs, Sales Coaches, Personal Shoppers, and Campaign Agents.
These agents are autonomous applications that provide 24/7 specialized support to employees or customers across multiple channels like web, mobile, WhatsApp, and Slack.
Microsoft is launching the next wave of Copilot, integrating web, work, and Pages as a new design for knowledge work. There’s also a bunch of Improvements being made to Copilot in various Microsoft 365 apps.
With GPT-4o and enhanced orchestration, Copilot responses are now more than two times faster on average. Response satisfaction has improved by nearly three times, so the improvements are definitely noticeable.
Copilot Pages (Perplexity called and wants its naming back…) is described as the first new digital artifact for the AI age, which allows users to edit, add to, and share AI-generated content.
Amazon launched Project Amelia, a generative AI assistant for sellers, offering tailored business insights, guidance, and actions using Amazon Bedrock technology. Sellers can consult Amelia for best practices and strategies, receiving tailored responses based on their data and market trends. It offers quick access to sales data, customer traffic insights, and product performance analysis to help monitor progress.
New Speech-Text Foundation Model and Turning Ideas Into Apps
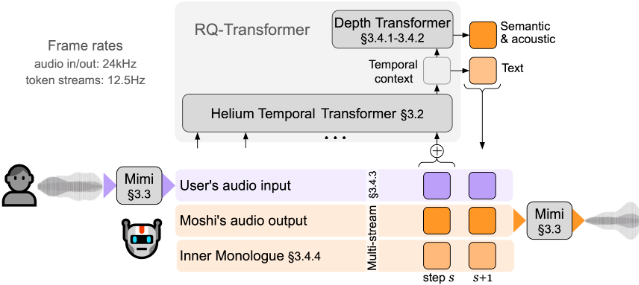
Moshi overview. (Source)
Kyutai Labs debuted a new speech-text foundation model called Moshi. It uses Mimi, a SOTA streaming neural audio codec that processes 24 kHz audio down to a 12.5 Hz representation with a bandwidth of 1.1 kbps.
The model consists of two main components:
A small Depth Transformer for inter-codebook dependencies
A large 7B parameter Temporal Transformer for temporal dependencies
Mimi outperforms existing non-streaming codecs like SpeechTokenizer and SemantiCodec in terms of efficiency and quality Moshi achieves a theoretical latency of 160ms (80ms for Mimi's frame size + 80ms of acoustic delay), with practical latency as low as 200ms on an L4 GPU.
The trend of accessible coding seems to be continuing with Llamacoder, which lets you enter a simple prompt to turn your idea into a fully developed app within a matter of minutes. Keep in mind that it’s only for smaller apps though.
It uses Llama 3.1 405B for code generation and Together AI for LLM inference - a nice combination that allows for efficient processing of prompts and code generation.
There’s also other features in the works currently, such as adding support for multiple programming languages and plans for more customization options in the future.
From Whale Songs to Cellular Automata
Google decided to go in a different direction with a unique AI application. They developed a whale bioacoustics model that can identify eight whale species and multiple vocalizations, including the Bryde's whale "Biotwang" sound. This is important for protecting whales that live in remote environments, since it’s hard to find them through other methods.
The model uses spectrograms to classify twelve whale vocalization classes, offering detailed species identification and recognizing various vocalization types. Results were certainly impressive since it showed high accuracies across different whale species, excelling in identifying complex sounds like "boings" and "gunshot" calls.
As such, it’s had some notable implications for discoveries about whale populations, movements, and behaviors.
More AI applications in the life sciences were seen last week with LifeGPT, a generative transformer model designed to simulate Conway's Game of Life (Life). Life is a cellular automaton simulation, which are models of computation that are useful in areas like biology.
The issue is that algorithms within cellular automata like Life are tough to model and predict due to sensitivity of initial conditions and the fact that prior understanding is needed. LifeGPT helps us solve this issue by simulating Life without needing prior knowledge.
The model is trained on various grid configurations, allowing it to generalize across different grid sizes and periodic boundary conditions effectively. LifeGPT accurately captures the complex dynamics of cellular automata with near-perfect accuracy.
We also saw the introduction of the "autoregressive autoregressor" method, which allows for recursive simulation of Life using LifeGPT for long-term predictions.
As a result, it would help design models that would have big implications for areas like bioinspired materials and tissue engineering.

A note from our partner
At any given moment, almost 100 in-person AI events, from hackathons to conferences, workshops, and meetups, are scheduled in the Bay Area alone. Subscribe to GenerativeAISF.com to discover and register for AI events that match your interests and get a weekly curated list of all the upcoming events and Sahar's top recommendations
Advancements in AI Research
One paper really stood out since it made an interesting parallel that we thought we’d never see between quantum mechanics and LLMs. Progress was also made in applying AI for scientific research tasks and dealing with limitations that traditional OCR systems had a tough time with.
AI Outperforms Experts in Scientific Research Tasks with PaperQA2
Researchers from FutureHouse developed PaperQA2, which showed SOTA performance in synthesizing scientific knowledge. Creating AI systems that can accurately and reliably help with scientific research tasks has been an issue for quite some time, so this paper helps address a key issue.
PaperQA2 used a frontier language model optimized for improved factuality, combined with an agentic approach to information retrieval and synthesis.
The system uses a multi-step process involving paper search, evidence gathering, and answer generation - all orchestrated by an agent model. But what really stands out is the Reranking and Contextual Summarization (RCS) step, which improves the relevance and quality of retrieved information.
The researchers evaluated PaperQA2 on three real-world tasks:
Answering scientific questions
Generating Wikipedia-style summaries
Detecting contradictions in scientific literature
PaperQA2 matched or exceeded human expert performance across these tasks. For example, it achieved superhuman precision on the LitQA2 question-answering benchmark and produced more accurate and better-cited Wikipedia-style summaries than existing human-written articles.
GOT's Comprehensive Solution for Visual Data Extraction
General OCR Theory (GOT) handles the limitations of traditional OCR systems in handling diverse types of artificial optical signals, from plain text to complex formulas and charts. It’s a unified end-to-end model consisting of a high-compression encoder and a long-context decoder.
The encoder, with about 80M parameters, processes 1024x1024 input images and compresses them into 256x1024 dimensional tokens.
The decoder, with 500M parameters, supports an 8K max token length for handling long-context scenarios.
They developed a multi-stage training strategy, including decoupled pre-training of the encoder, joint training with a new decoder, and further post-training. They also created specialized data engines for synthetic data production to support each training stage.
Results show that GOT outperforms existing models on various OCR tasks, including plain text recognition, formatted document understanding, and more specialized tasks like sheet music and chart recognition. For example, on the ChartQA-SE benchmark, GOT achieved an AP@strict score of 0.747, surpassing other models including GPT-4V and Qwen-VL.
LLMs and Quantum Mechanics: The Surprising Connection in Memory Models
Researchers from The Hong Kong Polytechnic University proposed a new framework for understanding memory in LLMs in a way that you wouldn’t have thought of.
They drew some pretty interesting parallels to quantum mechanics to answer the fundamental question of whether LLMs truly possess memory and, if so, how it functions compared to human memory.
The study leverages the Universal Approximation Theorem (UAT) to explain the memory mechanism in LLMs. They argue that LLM memory operates like "Schrödinger's memory" - it only becomes observable when a specific memory is queried, and its existence can’t be determined otherwise.
They demonstrated this concept through experiments on various LLMs, including fine-tuning models on poetry datasets to assess their memory capabilities.
Results show that LLMs can exhibit remarkable memory performance, with some models able to memorize nearly 100% of 2,000 poems after limited exposure. The study also revealed memory performance decreases as input text length increases, mirroring human memory limitations.
Frameworks We Love
Some frameworks that caught our attention in the last week include:
Vista3D: Rapid and consistent 3D object generation from a single image, using a two-phase approach.
NSSR-DIL: Reformulates image super-resolution as computing the inverse of degradation kernels, rather than directly generating high-resolution images from low-resolution inputs
MoRAG: Text-based human motion generation that enhances motion diffusion models by leveraging additional knowledge from an improved motion retrieval process
If you want your framework to be featured here, reply to this email saying hi :)
Conversations We Loved
Don't worry, no fruit were harmed (or community noted) in our selection. One of our pics of the week went into depth about real-world usage patterns of data warehouses stood out since it goes against the common assumptions about these systems.
Another post also grabbed our attention, which looked at cloud pricing for Kafka deployments, showing that there’s a big disparity between cloud costs and on-premise hardware capabilities for data streaming workloads.
Rethinking Data Infrastructure and Processing
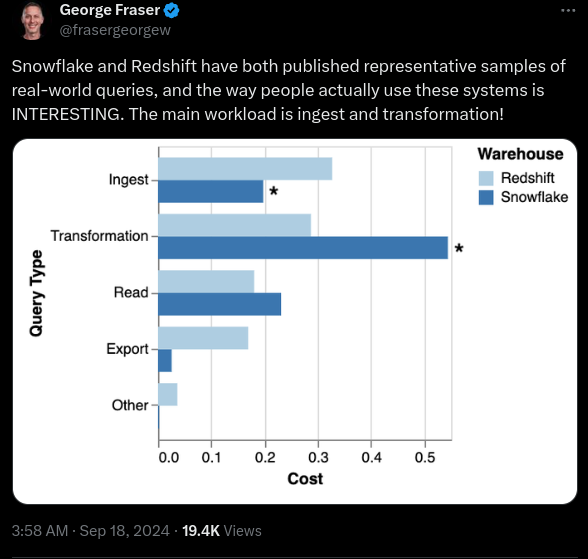
Fraser looked usage patterns of data warehouses. (Source)
There was a deep dive into the real-world usage patterns of data warehouses, courtesy of George Fraser, CEO of Fivetran. His analysis of query samples from Snowflake and Redshift offered some surprising insights that challenge common assumptions about how these systems are used in practice.
The post highlights that data warehouses are mainly used for ETL (Extract, Transform, Load) tasks, not just for business intelligence. Most queries are small, scanning only about 100 MB of data, which challenges the focus on massive scalability and has important implications for data infrastructure and processing.
Kozlovski’s post about cloud pricing for Kafka deployments. (Source)
Kozlovski’s breakdown of cloud pricing for Kafka deployments gained a lot of attention on X as it exposed the disparity between cloud costs and on-premises hardware capabilities for data streaming workloads.
He explained how a modest 30MB/s Kafka cluster could rack up over $110,000 in annual costs, with network traffic alone accounting for $88,300 of that sum. It shows a fundamental misalignment between cloud pricing structures and the needs of data-intensive applications.
He also went into the reasons behind this pricing anomaly and explored potential solutions. From optimizations like "fetch from follower" to more radical approaches like WarpStream's innovative design, the discussion brought the ongoing struggle between cloud convenience and cost-effectiveness to light. Interesting.
Money Moving in AI
While Microsoft launched the next wave of Copilot, they also announced a partnership with BlackRock where they’ll invest $30 billion for AI infrastructure development support. Other news included Nvidia thinking about acquiring OctoAI for $165 million.
In terms of successful funding rounds, Sakana AI and Black Forest Labs raised $210 million and $100 million respectively.
OpenAI's $150B Sprint
In the next episode full of plot twists worthy of a soap opera, Apple has decided to sit out the $6.5 billion OpenAI's (allegedly oversubscribed?) funding round, leaving Microsoft and Nvidia to fight over the last dance. Rumor has it, Microsoft is sweetening the pot with an extra $1 billion, probably hoping to impress OpenAI with its deep pockets and irresistible charm. Beyond SoftBank at $500M, here's the list of other firms who are reportedly in talks to invest.
Microsoft and BlackRock’s Initial Investment of $30 Billion
Microsoft and BlackRock have announced a joint venture, the Global AI Infrastructure Investment Partnership, with an initial investment of over $30 billion to support the development of AI infrastructure, focusing on data centers and energy resources.
The partnership, which includes MGX as a general partner and expertise from Nvidia, aims to address the growing demand for computational power required by AI models while ensuring sustainable development.
Sakana AI Raises $210 Million in Series A Funding
Sakana AI, an NVIDIA-backed startup, has raised over $210 million in a Series A funding round, doubling its initial target of $100 million and achieving a valuation exceeding $1.5 billion just a year after launch.
The company has gained popularity for developing a method to automate the integration of multiple foundational models.
Nvidia May Acquire OctoAI for $165 Million
Nvidia is reportedly considering acquiring OctoAI, a startup that develops software to enhance AI model efficiency, for $165 million.
This potential acquisition follows OctoAI's recent collaboration with Nvidia to integrate NIM into its generative AI platform, aiming to serve various enterprise use cases.
Black Forest Labs Reported to Raise $100 Million
Black Forest Labs, the startup behind Grok's image generator (and competitor to Midjourney), is reportedly raising $100 million at a $1 billion valuation, just two months after emerging from stealth with $31 million in funding.
Previously, the startup’s valuation was around $150 million during the last funding round, so it’s definitely a big increase.