- GenAI360 - Weekly AI News
- Posts
- Gemma 2 2B > GPT-3.5, Open-Source FLUX-1 vs Midjourney, GitHub Takes on Hugging Face
Gemma 2 2B > GPT-3.5, Open-Source FLUX-1 vs Midjourney, GitHub Takes on Hugging Face
Plus, EU AI Act comes into force

Before we start, share this week's news with a friend or a colleague:
Key Takeaways
Google unveiled the new generation of Gemma 2 models, with the 2B model showing strong performance while running on-device along with two other models that focus on privacy and transparency.
Apple introduced two new foundation language models (AFM-on-device and AFM-server), with the on-device model outperforming Llama-3 8B and the server model outperforming GPT3.5.
Salesforce AI Research introduced MINT-1T, the first trillion token interleaved dataset that outperformed the previous state-of-the-art interleaved dataset, OBELICS.
Black Forest Labs released the FLUX.1 suite of models which outperforms Midjourney-V6.0 in aspects like visual quality by incorporating rotary positional embeddings and parallel attention layers.
Stanford University researchers created a comprehensive benchmark for solving predictive tasks over relational databases using graph neural networks, aimed at generating large-scale training data for autonomous driving applications.
Got forwarded this newsletter? Subscribe below👇
The Talk of the Day: And Then There Were Three…
OpenAI has just lost more of the original 11 founders. President Greg Brockman, co-founder John Schulman, and product leader Peter Deng have left the ChatGPT developer.
After AI safety researcher Jan Leike left to work at Anthropic on the AI alignment problem, Schulman took over as the leader of OpenAI's alignment science team, also called the "post-training" team. Now, he'll continue this mission at Anthropic, following in Leike's footsteps.
While it's not yet clear where Deng will go, Brockman has decided to take a sabbatical ‘to relax since co-founding OpenAI 9 years ago'.
Only three of OpenAI’s 11 original founders remain: OpenAI CEO Sam Altman, Brockman (who hasn't quit officially), and Wojciech Zaremba, lead of language and code generation.
The Latest AI News
Google’s Gemma 2 2B outperformed GPT-3.5 despite being a lot smaller, meaning that competition for the GPT models is only increasing.
Meanwhile, the hardware race is heating up with AMD challenging NVIDIA's dominance and Samsung ramping up chip production, so we might see a big shift in the AI infrastructure landscape.
The Next Generation of Gemma 2 Models & Salesforce's MINT-1T
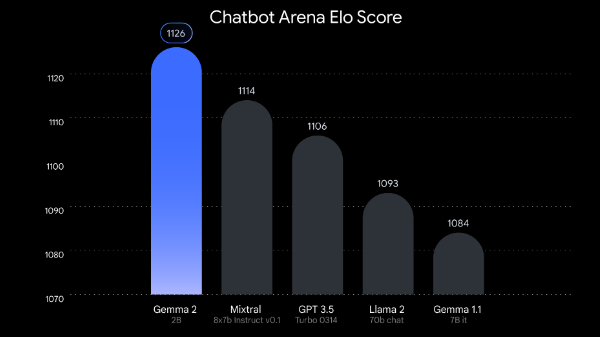
Gemma 2 outperforms much larger models. (Source)
Three new models were added to the Gemma 2 model family by Google last week.
Gemma 2 2B is a smaller, yet more efficient model that outperforms larger models while still having safety advancements built into it. The 2B model even outperformed every GPT3.5 model on Chatbot Arena.
In addition to Gemma 2 2B, ShieldGemma and Gemma Scope were also introduced. ShieldGemma boosts the privacy and security of AI models by protecting user data, while Gemma Scope offers tools and techniques to provide a better understanding of how AI decisions were made.
In other news, Salesforce AI Research presented MINT-1T - the first ever trillion token interleaved dataset. So what’s the big deal about it?
Interleaved documents have a mixture of text and images, which means they can be used to train multimodal models for text and visual capabilities. Models like Chameleon showed just how effective interleaved data can be in achieving high performance for multimodal models.
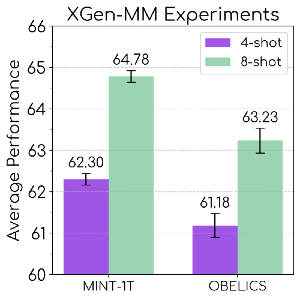
MINT-1T outperforms the previous leading interleaved dataset, OBELICS. (Source)
As a result, the chances of seeing much larger multimodal models in the future has increased drastically. In fact, this dataset is already being used to train the XGen-MM series.
Stability AI’s Double Play: Stable Fast 3D and S4VD
Stability AI has introduced Stable Fast 3D, a new AI model capable of generating 3D assets from a single image in 0.5 seconds. It’s a big leap in the field of AI-driven 3D content creation since it could change the way we look at game development, visual effects, and product design.
Stable Fast 3D's ability to quickly generate 3D assets challenges the traditional notion that high-quality 3D generation requires lengthy processing times. This could lead to new paradigms in real-time content creation and interactive design processes.
The other model Stability AI released was SV4D, which generates a 4D image matrix from a single-view video of an object. It generates 40 frames at 576x576 resolution and outperforms its predecessor, SV3D.

SV4D offers better video synthesis than SV3D by boosting video frame consistency. (Source)
But we’re a little surprised to see more model releases since Jasper bought ClipDrop (an image creation and editing platform) from Stability earlier in the year.
Meta's SAM 2, Runway's Gen-3 Alpha, and FLUX.1: The Next Wave of Important AI Models
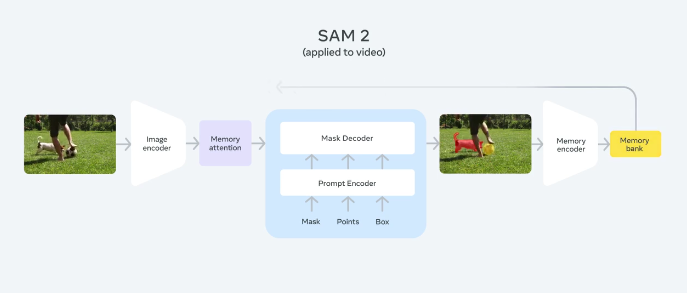
How SAM 2 works. (Source)
Meta has introduced Segment Anything Model 2 (SAM 2), which builds upon the success of its predecessor by offering improved accuracy, efficiency, and versatility in segmenting objects within images.
The fact that the model can annotate 8.4 times faster than using SAM 1 per frame is pretty impressive. It addresses a critical need for real-time applications in fields like autonomous driving and augmented reality. Note that SAM 1 had a massive impact on annotation companies (most of which pivoted into RLHF), so SAM 2 being able to annotate a lot faster is a big deal.
Yet another model in the AI image space we saw was Gen-3 Alpha by Runway. It demonstrates enhanced capabilities in understanding and executing complex prompts.
Meanwhile, Midjourney is facing some serious competition with the release of FLUX.1 by Black Forest Labs, which offers better performance in aspects like image detail and style diversity,
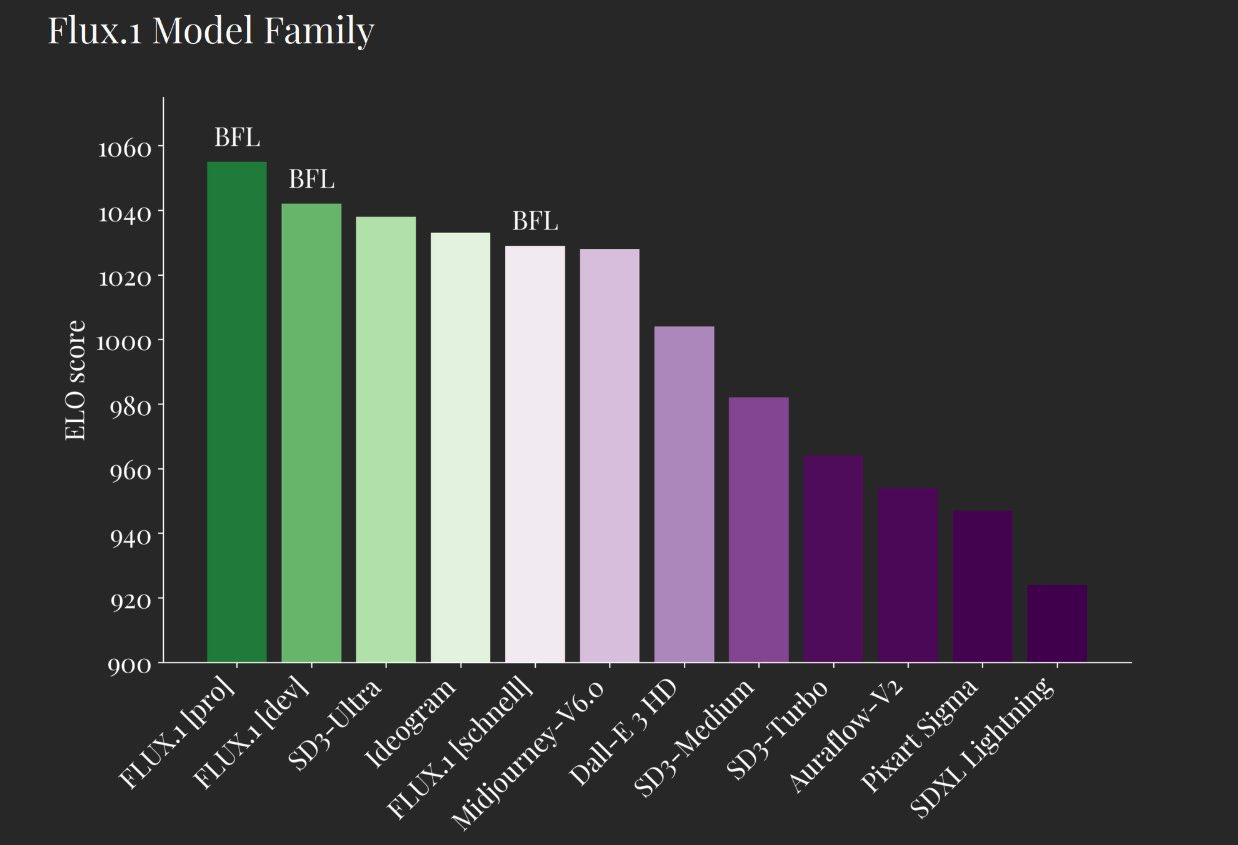
FLUX.1 models achieved the highest ELO. (Source)
These models use a hybrid architecture of multimodal and parallel diffusion blocks. They built on top of flow matching and included parallel attention layers to achieve such impressive results that drastically outperforms previous models.
NVIDIA Delays, and AMD vs Samsung vs Apple: The AI Chip Wars Heat Up
We previously saw that Nvidia made its move in the AI chip market by developing a new chip just for the Chinese market. The story continues with AMD reporting significant revenue gains and unveiled plans to compete more aggressively with Nvidia in the AI chip market.
AMD's focus on both CPUs and GPUs for AI workloads suggests a multi-pronged approach to AI computing, which could influence future hardware architectures for AI systems.
In other news, Samsung Electronics reported a remarkable 50% increase in sales of its High Bandwidth Memory (HBM) chips, a critical component in AI accelerators.
Samsung's success in this sector could reshape the competitive landscape of the semiconductor industry, with implications for other major players like Nvidia and AMD.
Nvidia’s chip dominance was further challenged by Apple last week (who, as we know, produces their own chips). Apple went with Google TPUs instead of Nvidia to train their models, despite Nvidia controlling a massive 80% of the AI chip market.
Apple was using two types of Google TPUs instead of relying on Nvidia GPUs for AI models used in iPhones.
Nvidia also reported delays in the next AI chip (Blackwell B200) because of a “design flaw”.
GitHub Challenges Hugging Face
GitHub introduced GitHub models, which is designed to enhance software development workflows, giving Hugging Face some serious competition. These models are integrated into GitHub Copilot and other GitHub products to improve coding efficiency and accuracy.
While Hugging Face excels in providing a wide range of models for various machine learning applications, including NLP, its broader focus may not cater as specifically to the coding needs of developers as GitHub Models does. This is seen by the fact that Hugging Face was reported to have 700,000 LLMs last June.
In terms of users, GitHub has 100 million users, while Hugging Face was reported to have 4 million users in August 2023. (this number is likely to be higher now), so GitHub can distribute the models far more efficiently than HF.
OpenAI Endorses Senate Bills and EU AI Act is in Force
There wasn’t much from OpenAI in terms of model releases in the couple weeks aside from GPT-4 mini, but they endorsed three Senate bills last week. These bills include:
Probably doesn’t come as a surprise knowing that OpenAI is one of the biggest AI companies out there, so they certainly wouldn’t mind having a say on topics like this to get on the good side of lawmakers.
In other news, the EU AI Act we discussed before has now gone into force. It’s worth pointing out that it’ll take some time before all the rules will be applied though.
Specifically, it focuses on ethical development and deployment of AI within EU, categorizing AI applications based on their risk level. Higher risk means stricter rules, but it won’t affect the popular chatbots we all know and love like ChatGPT since most of them are considered to be minimal risk.
It’s one of the first comprehensive legal frameworks for AI, but it’s unlikely to be the last as we move forward into a future with more powerful models.
Advancements in AI Research
From MindSearch's innovative approach to complex information retrieval to the practical advancements in video object detection, we're seeing AI tackle increasingly nuanced and real-world challenges. On-device models also continued to advance with Apple’s foundation language model paper, showing impressive results across multiple benchmarks.
Apple's On-Device AI: How Small Models Achieve Big Results
Aside from the news about Apple not using Nvidia chips, they also introduced two new foundation language models designed to power Apple Intelligence features across iOS, iPadOS, and macOS.
The models, AFM-on-device (~3 billion parameters) and AFM-server (larger server-based model), aim to perform a wide range of tasks efficiently, accurately, and responsibly while addressing the challenges of running AI on consumer devices and maintaining user privacy.
To achieve this, Apple employed several innovative techniques:
Architecture optimization: The models use a dense decoder-only architecture with improvements like grouped-query attention and RoPE positional embeddings for long-context support.
Efficient training: A three-stage pre-training process (core, continued, and context-lengthening) using a diverse, high-quality data mixture and custom optimizer.
Adapter-based fine-tuning: LoRA adapters for task-specific optimization without changing the base model.
AFM-on-device outperforms larger open-source models like Mistral-7B in instruction following and writing tasks, while AFM-server achieves competitive performance against GPT-3.5 and GPT-4 in various benchmarks.
This means GPT3.5 isn’t just facing competition from Google’s Gemma 2 2B, but also from Apple’s AFM-on-device model.
Can AI Mimic Human Cognitive Processes for Complex Web Searches?
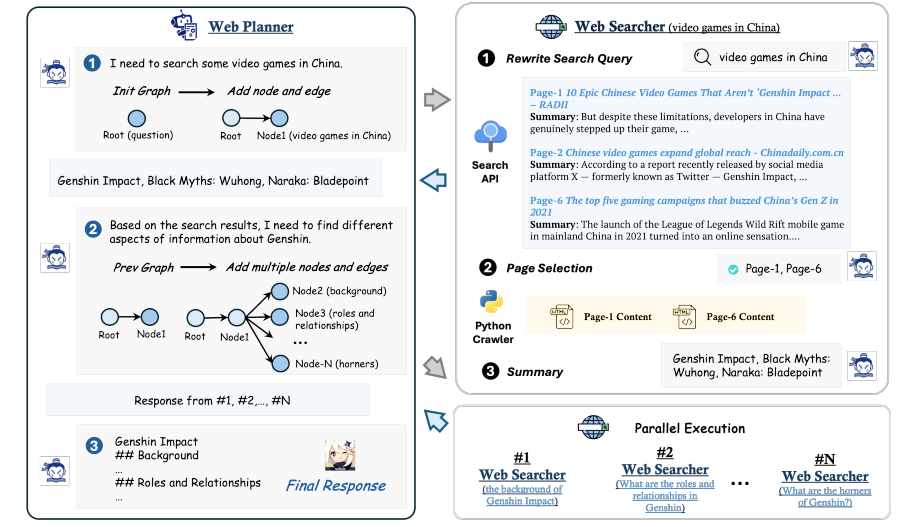
Framework of MindSearch. (Source)
MindSearch aims to overcome the limitations of current AI search methods, which often struggle with accurately retrieving and integrating information for complex queries that require multi-step reasoning and in-depth analysis.
To achieve this, the team developed a simple yet effective LLM-based multi-agent framework consisting of a WebPlanner and WebSearcher. The WebPlanner models the human mind's multi-step information seeking process as a dynamic graph construction, decomposing user queries into atomic sub-questions.
Meanwhile, the WebSearcher performs hierarchical information retrieval with search engines and collects valuable information for the WebPlanner.
Notably, responses from MindSearch based on InternLM2.5-7B are preferred by humans over those from GPT-4o and Perplexity. It might change how we approach complex information retrieval and integration tasks in various domains.
Feature Selection and Aggregation Boost Accuracy and Speed in Video Object Detection
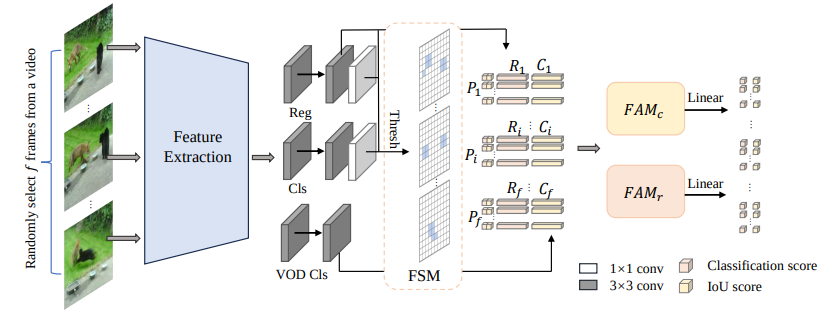
Schematic of the framework. (Source)
Researchers from Tianjin University have introduced a different approach to video object detection (VOD) that addresses the challenges of high across-frame variation in object appearance and diverse deterioration in video frames.
To achieve this, the team developed two key components:
A Feature Selection Module (FSM) to reject low-quality candidates and reduce computational expense
A Feature Aggregation Module (FAM) that uses feature similarity measurements to guide the aggregation process.
The approach incorporates an average pooling operator on reference features to alleviate shortcomings of commonly-used cosine similarity.
Results demonstrate that their model achieves a new record performance of 92.9% AP50 at over 30 FPS on the ImageNet VID dataset using a single 3090 GPU. It offers a practical solution for video object detection that balances accuracy and speed, making it suitable for large-scale or real-time applications.
New Benchmark for AI in Relational Databases

RELBENCH overview. (Source)
Researchers from Stanford University and Kumo.AI have introduced RELBENCH, a comprehensive benchmark that aims to address the challenge of generating large-scale, high-quality training data for machine learning tasks in autonomous driving, particularly for map perception and related applications.
To achieve this, they developed an extension to the Lanelet2 framework called lanelet2_ml_converter, which enables the generation of diverse training labels directly from HD maps.
The extension introduces features such as:
Compound labels for independence from map annotation artifacts
Traceability of labels to original map elements
Support for varying local reference frame poses
Results showed that Relational Deep Learning (RDL) models trained on RELBENCH outperform traditional feature engineering approaches, reducing human work hours by 96% and lines of code by 94% on average.
It’s important because it provides a foundational infrastructure for future research into RDL, which could speed up the development and validation of machine learning models for autonomous vehicles and other domains that rely on relational databases.
Frameworks We Love
Some frameworks that caught our attention in the last week include:
Torchchat: A library by Meta AI that enables running large language models like Llama 3 and 3.1 locally on laptops, desktops, and mobile devices with high performance
AI router chat: Personal chatbot arena that adapts to the user
PDF Extract kit: Comprehensive toolkit for high-quality content extraction from PDF documents.
If you want your framework to be featured here, reply to this email and say hi :)
Conversations We Loved
Last week’s discussions gave us plenty to think about when it comes to building and using large-scale AI systems. From GPT-4o's impressive 64K output leap to a pharma CIO's candid take on Microsoft's Copilot, these discussions highlight how the AI world is grappling with both technical advances and real-world applications.
GPT4-o's 64K Leap
OpenAI's experimental release of GPT-4o with a 64K output capability has sparked discussion in the AI community about the future of large-scale language model applications.
The 64K output opens up new possibilities for tasks like full document translation, comprehensive structured data extraction, and long-form content generation. At $6/$18 per million input/output tokens, the new alpha model is slightly more expensive than standard GPT-4o ($5/$15 per million input/output tokens). But it’s a little difficult to tell if increased output capability is worth the additional cost for different use cases.
It could lead to more efficient workflows in industries like translation, data analysis, and content creation. However, it also raises important questions about the cost-effectiveness of AI solutions and the need for careful consideration of use cases that truly benefit from such extended output capabilities.
Why Was the Copilot AI Deal Cancellation a Big Deal?
A recent revelation from a pharmaceutical company's CIO provided some food for thought about the real-world value of enterprise AI tools. The CIO's decision to cancel their Microsoft 365 Copilot subscription after a six-month trial period raises important questions about the gap between AI's promised potential and its current practical applications.
The CIO's comparison of Copilot's slide-generation capabilities to "middle school presentations" highlights the need for AI tools to deliver tangible, high-quality results that justify their cost.
With Copilot doubling the cost of Microsoft 365 licenses, there's a growing debate about how to price AI capabilities in a way that aligns with their perceived value. Microsoft's massive investments in AI infrastructure raise questions about how tech giants will recoup these costs and what it means for future pricing and product strategies.
Money Moving in AI
It’s a little unusual to be mentioning Reddit in an AI newsletter, but they acquired a company called Memorable AI last week. In terms of successful funding rounds, Aisles and Sybil secured $500 million and $11 million respectively.
Aisles Secures $500 Million in Private Equity Round and Introduces Aisles Enterprises
Aisles has secured $500 million in a private equity round to fuel its expansion into tech startup investments. The company introduced Aisles Enterprise, a new branch dedicated to identifying and supporting promising AI and tech startups.
Sybil Secures $11 Million in Seed Funding Round
Sybill, a startup developing an AI assistant for salespeople, has secured $11 million in seed, led by Khosla Ventures. The company's AI tool aims to reduce the administrative burden on sales teams by automating tasks like note-taking, data entry, and follow-up scheduling.
Reddit Acquires Memorable AI
Reddit has made its first acquisition since going public in March, purchasing ad-optimization company Memorable AI for an undisclosed amount. Memorable AI uses artificial intelligence to analyze audience reactions to content, helping to determine what resonates with specific groups.