- GenAI360 - Weekly AI News
- Posts
- Second GPT-4 Level Open Model, International Mathematical Olympiad vs DeepMind's LLM + RLHF
Second GPT-4 Level Open Model, International Mathematical Olympiad vs DeepMind's LLM + RLHF
Plus, Nvidia Makes Chips for China

Before we start, share this week's news with a friend or a colleague:
Key Takeaways
Meta's Llama 3.1 demonstrates advanced reasoning capabilities, solving complex math puzzles that have stumped other AI models, including GPT-4.
Mistral releases Large 2, a 123 billion parameter model, claiming performance on par with offerings from OpenAI and Meta in code generation, mathematics, and reasoning.
Google DeepMind unveils AlphaGeometry, an AI system capable of solving International Mathematical Olympiad (IMO) geometry problems at a silver medal level.
RT-DETRv2 improves upon RT-DETR by offering greater flexibility in multi-scale feature extraction and achieving enhanced performance without speed loss across various detector sizes.
LazyLLM is a dynamic token pruning method for efficient long context LLM inference, accelerating the pre-filling stage of LLama 2 7B by 2.34x while maintaining accuracy.
Got forwarded this newsletter? Subscribe below👇
The Latest AI News
From Meta's Llama 3.1 solving complex math puzzles to Mistral's Large 2 challenging industry giants, we're seeing model capabilities and applications grow rapidly. Meanwhile, controversies around data usage and the race for market dominance remind us that the path to AI advancement isn’t without its ethical and practical challenges.
We're launching a new certification program. Do you have 45 minutes to test it and give us feedback?Help shape a new GenAI360 certification test |
Llama's Math Prowess, Mistral's Leap, and NVIDIA's Miniature Marvels
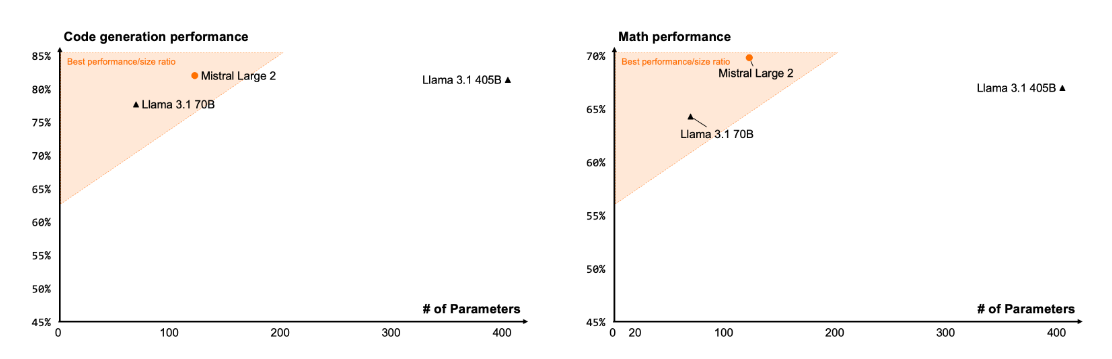
Mistral Large 2 outperforms Llama 3.1 at code generation and math. (Source)
We previously covered how Llama 3.1 is attracting considerable attention due to its impressive benchmark performances and potential to challenge other flagship models.
Last week, Llama 3.1 continued to gain attention with a notable demonstration. In it, Llama 3.1 successfully solved a complex math puzzle involving candle lengths, displaying advanced logical reasoning that has left other AI models stumped.

A tough math problem that Llama 3.1 could handle while other models were unable to solve it. (Source)
The model correctly deduced that the longest remaining candle (option 3 in the image above) was the first to be blown out, a task that even GPT-4 has struggled with in similar tests.
But Meta wasn’t the only one to recently release a state-of-the-art LLM.
A day after Meta's Llama 3.1 announcement, Mistral released its new flagship model, Large 2, claiming performance on par with the latest offerings from OpenAI and Meta in code generation, mathematics, and reasoning.
With 123 billion parameters, Large 2 reportedly outperforms Meta's recently released Llama 3.1 405B in code generation and math tasks, despite having less than a third of the parameters. The creators also claim SOTA for function calling.

Large 2 and Llama 3.1 are both close to GPT-4o in terms of performance. (Source)
Mistral emphasizes reduced hallucination issues and improved multilingual support, covering 12 languages and 80 coding languages. The model features a 128,000 token context window and is available on major cloud platforms.
Of course, you can’t have an AI news roundup without mentioning Nvidia somewhere. They introduced Minitron, a new family of small language models (SLMs) derived from their larger Nemotron-4 15B model. The Minitron models, available in 8B and 4B parameter sizes, are created through a combination of pruning and knowledge distillation techniques.
This approach significantly reduces the computational cost of training, requiring up to 40x fewer tokens and resulting in a 1.8x reduction in overall compute costs for the model family.
Despite their smaller size, Minitron models demonstrate competitive performance, with up to 16% improvement in MMLU scores compared to models trained from scratch, and comparable results to other community models like Mistral 7B, Gemma 7B, and Llama-3 8B.
DeepMind Advances Math
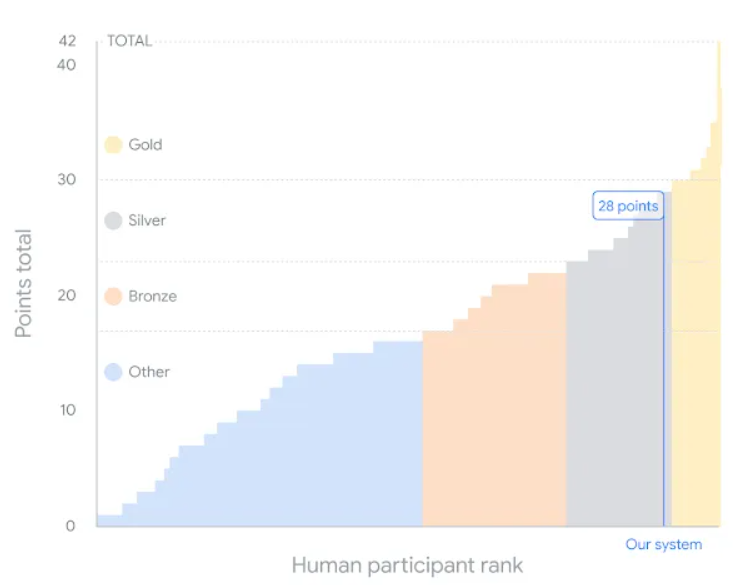
AlphaGeometry earned 28 out of 42 points, putting it on the same level as a silver medalist. (Source)
Google DeepMind unveiled AlphaProof, a new reinforcement-learning based system for formal math reasoning, and AlphaGeometry 2, an improved version of our geometry-solving system. Together, the two present an AI system capable of solving International Mathematical Olympiad (IMO) geometry problems at a silver medal level (4 out of 6 problems).
Traditional AI systems have struggled with formal mathematical proofs due to limited training data, while NLP, despite access to vast data, often produces plausible but incorrect proofs.
AlphaProof solves this problem by bridging the gap, combining a fine-tuned Gemini model with reinforcement learning techniques similar to AlphaZero. Using the formal language Lean, AlphaProof generates verifiable proofs and continuously improves by learning from its own verified solutions. Read more on what's special about the AlphaProof and AlphaGeometry 2 here.
The Middle East's 4 Billion-Dollar Bet and Nvidia's Chinese Gambit
Abu Dhabi is set to create a major player in the AI and space technology sectors with the merger of Yahsat and Bayanat AI to form Space42.
The new entity, valued at $4 billion, aims to become the Middle East and North Africa's largest AI-powered space technology company. Space42 will integrate satellite communications and business intelligence to position itself for both regional and global opportunities.
Alongside the new Minitron models, Nvidia also made moves in the AI chip market. They are reportedly developing a new AI chip specifically tailored for the Chinese market, aiming to comply with U.S. export restrictions while maintaining their presence in this crucial market. A couple of weeks ago, OpenAI was in talks to develop their own AI chip.
Nvidia’s newest chip, known internally as the H20, is a scaled-down version of Nvidia's flagship H100 AI accelerator, designed to meet the U.S. government's performance thresholds for exports to China.
This move comes as Nvidia seeks to balance regulatory compliance with its business interests in China, which accounted for 21% of its revenue in the most recent fiscal year. The H20 is expected to be part of a new product line that includes the L20 and L2 chips, all aimed at addressing the growing demand for AI hardware in China while navigating complex geopolitical challenges.
Runway Accused of Allegedly Using Publicly Available YouTube Videos
Video generation startup Runway AI is facing controversy over its AI training practices. According to a report by 404 Media, the company allegedly used thousands of publicly available YouTube videos to train its Gen-3 Alpha model, which generates 10-second videos.

Tech Review MKHB pointed out that a lot of his videos were used by Runway to train their video generator. (Source)
The accusation is based on a leaked internal spreadsheet, which suggests Runway scraped content from popular YouTube creators, brands, and even pirated films. While this has sparked debate about the ethics and legality of using publicly available content for AI training, experts note that the legal landscape around such practices remains unclear.
This isn’t the first time we’ve heard of this type of accusation, as OpenAI reportedly used over a million hours of YouTube videos to train GPT-4 last April.
How Machines are Calling the Bluff on Human Poker Champions
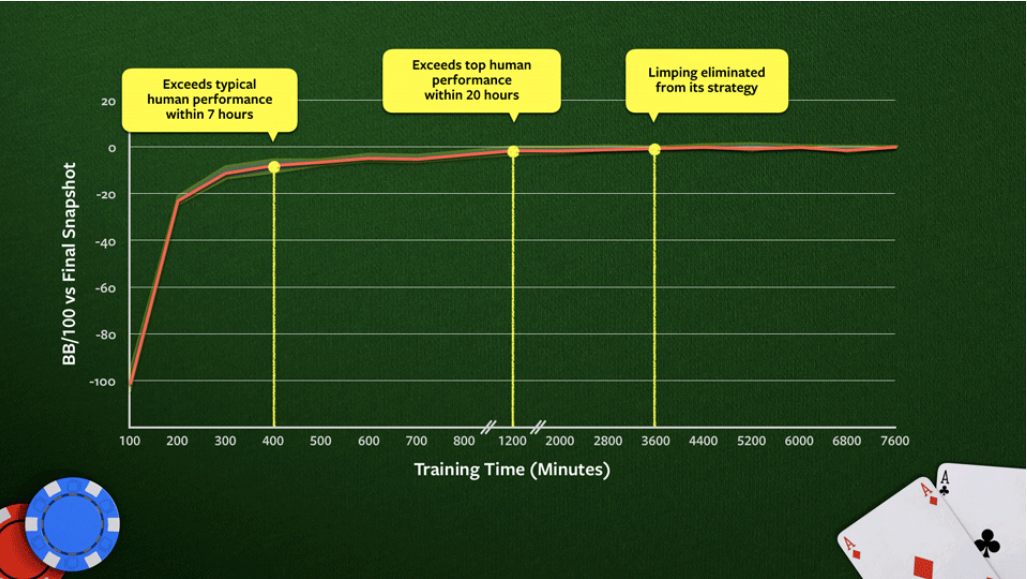
How Pluribus’ blueprint strategy improves while training on a 64-core CPU. (Source)
Facebook AI and Carnegie Mellon University have developed Pluribus, the first AI to consistently beat elite human professionals in six-player no-limit Texas Hold'em poker.
We’ve seen AI win against the World Go champion before, but the fact that AI was able to win in poker is pretty impressive. It's the first time an AI system has outperformed humans in a complex game with more than two players or teams.
Pluribus won decisively against top poker professionals, including World Series of Poker champions, earning an estimated $1,000 per hour against five human players.
The AI's success stems from its ability to handle hidden information and multiple players efficiently. Pluribus uses self-play to develop its strategy without human input and employs a novel search algorithm that looks only a few moves ahead rather than to the end of the game.
Pluribus was trained using relatively modest computing resources - less than $150 worth of cloud computing. Contrary to popular belief, you don’t need extensive computational resources to pull off impressive feats like this.
OpenAI's SearchGPT Met With Skepticism and Microsoft’s AI-Powered Feature for Search Results
OpenAI has introduced SearchGPT, a new search feature designed to provide "timely answers" to questions using web sources. The prototype, powered by GPT-3.5, GPT-4, and GPT-4o models, is currently available to a limited group of users and publishers.
While OpenAI positions SearchGPT as a more responsible AI search tool with clear attribution and publisher collaboration, the announcement was met with skepticism from industry observers.

SearchGPT gets its own demo… wrong
Funnily, just like Bard by Google back in the day (RIP), the first product demo shows a factual error. When mock user types “music festivals in boone north carolina in august,” SearchGPT pulls up a list of festivals, the first being An Appalachian Summer Festival. Then the tool tells the user the festival is on for dates when it’s officially closed (festival dates are from 6/29 - 7/27). But SearchGPT gives the dates as 7/29 to 8/16.
In the meantime, Microsoft also expanded its AI offerings by rolling out a beta of a new AI-powered feature for Bing search results, which provides concise summaries of web pages directly in the search results.
This feature is powered by GPT-4 and provides users with key information from websites without the need to click through.
Advancements in AI Research
Multi-agent research saw further advancements last week, handling issues with scalability. Moreover, autonomous driving saw some important progress with real-time object detection and training data generation.
Scaling Multi-Agent Simulations to Millions With AgentScope
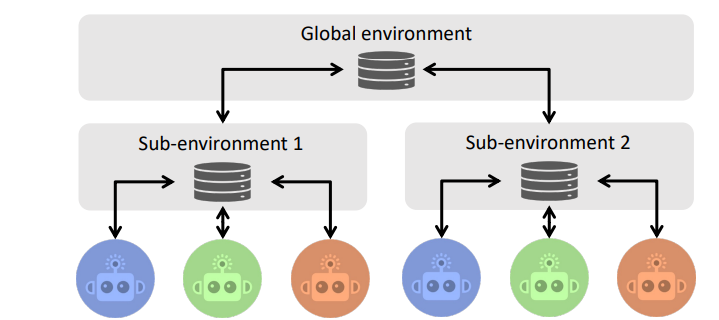
The multi-layer environment structure. (Source)
AgentScope addresses key challenges in conducting large-scale multi-agent simulations, including limited scalability, unsatisfied agent diversity, and effort-intensive management processes.
To tackle these issues, the authors:
Developed an actor-based distributed mechanism for improved scalability and efficiency
Provided flexible environment support for various real-world scenarios
Integrated tools for creating diverse agent backgrounds and managing large numbers of agents across multiple devices.
Their experiments demonstrate the ability to conduct simulations involving 1 million agents using only 4 devices, showing drastic improvements in scalability and efficiency compared to existing approaches.
By providing a comprehensive framework that addresses both technical and usability challenges, AgentScope lets researchers and developers conduct more realistic and complex simulations involving a massive number of diverse agents.
This could lead to valuable insights in fields such as social science, economics, and urban planning, where understanding the collective behavior of large populations is key.
Enhancing Real-Time Object Detection Performance with RT-DETRv2
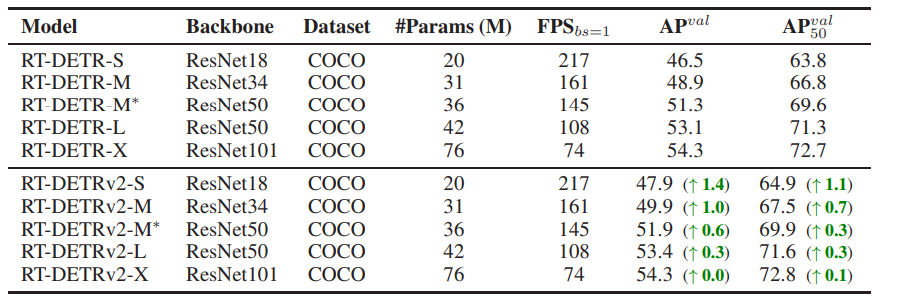
RT-DETRv2 shows notable improvements over its predecessor. (Source)
RT-DETRv2 addresses key challenges in real-time object detection, including the need for greater flexibility in multi-scale feature extraction, deployment constraints associated with DETRs, and performance optimization without sacrificing speed.
Researchers at Peking University proposed setting distinct numbers of sampling points for features at different scales in deformable attention, introducing an optional discrete sampling operator to replace the grid_sample operator, and implementing dynamic data augmentation.
The results show that RT-DETRv2 provides an improved baseline for RT-DETR with increased flexibility and practicality. It achieves enhanced performance without speed loss across various detector sizes.
By addressing deployment constraints and optimizing training strategies, RT-DETRv2 pushes the boundaries of what's possible in real-time object detection. It could certainly impact a wide range of applications, from autonomous driving to video surveillance.
Generating Diverse Training Data for Autonomous Driving
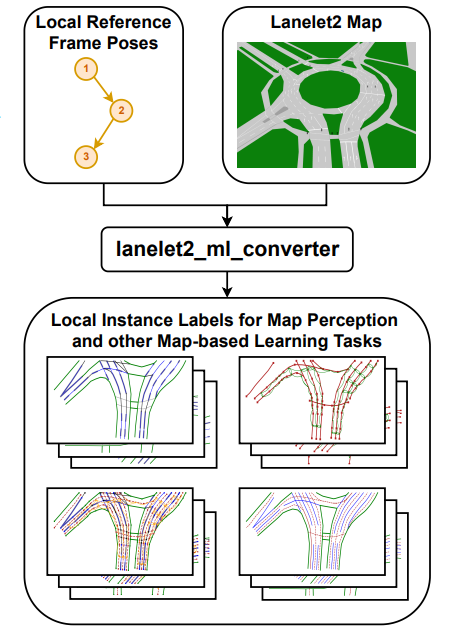
Applications of the software module. (Source)
Speaking of autonomous driving, this paper addresses the challenge of generating large-scale, high-quality training data for machine learning tasks in autonomous driving - particularly for map perception and related applications.
The authors propose an extension to the Lanelet2 framework called lanelet2_ml_converter. This extension enables the generation of diverse training labels directly from HD maps while maintaining compatibility with existing automated driving functionalities.
The extension introduces features such as:
Compound labels for independence from map annotation artifacts
Traceability of labels to original map elements
Support for varying local reference frame poses.
Results were impressive as they showed the proposed framework's flexibility and effectiveness in generating training data for various map perception tasks, including online HD map construction, topology inference, and map fusion.
It bridges the gap between HD maps used in automated driving and the growing need for large-scale, standardized training data in AI-based mapping and perception tasks.
Using LazyLLM to Accelerate LLM Inference with Dynamic Token Pruning

How LazyLLM differs from standard LLM. (Source)
LazyLLM addresses the challenge of slow first token generation in large language models when processing long prompts, which can significantly impact overall inference speed.
To solve this, the authors introduce a dynamic token pruning method that selectively computes key-value (KV) caches only for tokens deemed important for next token prediction in both the prefilling and decoding stages, allowing the model to adapt its token selection at each generation step.
Experiments across various tasks demonstrate that LazyLLM can accelerate the prefilling stage of the LLama 2 7B model by 2.34x while maintaining accuracy on multi-document question-answering tasks.
Notably, LazyLLM offers a generic method to improve the efficiency of LLM inference, particularly for long-context scenarios, without requiring model fine-tuning.
By focusing on optimizing the often-overlooked prefilling stage, LazyLLM provides a complementary approach to existing methods that primarily target decoding efficiency, potentially leading to more comprehensive improvements in LLM inference speed across various applications.
Frameworks We Love
TiCoSS: Tightens the coupling between semantic segmentation and stereo matching tasks for autonomous driving perception.
iNNspector: Comprehensive system for systematic debugging of deep learning models, providing interactive visualizations and tools to explore model architectures.
Structured financial data extraction: Extracts financial data from unstructured documents like balance sheets and financial statements using a combination of schema-based extraction with Pydantic, LLM, and the Indexify framework.
Conversations We Loved
Last week we saw discussions about the in-depth process that goes into building generative AI platforms, alongside the differences in the technicalities of terms like open-source and free models by using Llama 3 as an example.
Deep Dive Into Building a Generative AI Platforms

Huyen’s exploration of how to build a generative AI platform. (Source)
Chip Huyen, a prominent figure in machine learning systems, shared a comprehensive overview of building generative AI platforms, outlining common components and their implementations.
Is Llama 3.1 Really Open Source?
We don’t really think about it, but there are actually key distinctions between the terms open-source, open weights, and free models. However, Generative AI lead at AWS Eduardo Ordax brought this issue to light by using Llama 3.1 as an example.
𝗢𝗽𝗲𝗻 𝗦𝗼𝘂𝗿𝗰𝗲: you get the whole shebang—source code, hyperparameters, the original dataset, and all the juicy documentation. It's like getting the keys to a candy store and being told, "Go nuts!".
𝗢𝗽𝗲𝗻 𝗪𝗲𝗶𝗴𝗵𝘁𝘀: You can use the pre-trained model and even fine-tune it, but you won't get the original code or training methods (just like for Llama v3.1 and Mistral Large 2).
𝗟𝗶𝗰𝗲𝗻𝘀𝗶𝗻𝗴 𝗟𝗶𝗺𝗶𝘁𝗮𝘁𝗶𝗼𝗻𝘀: Llama 3.1 is released under the Llama 3.1 Community License Agreement. Commercial use is allowed, but with limitations. Conversely, Large 2 is allowed only for non-commercial news.
While downloading the model is free, the post points out the significant costs associated with deploying and running inference, challenging the notion of Llama 3.1 being entirely "free."
The highlights how the AI community needs to be more accurate in its use of terms like "open source" and "free," since these have specific implications for model development and adoption.
Money Moving in AI
Cowbell and Harvey had successful Series C funding rounds, raising $60 million and $100 million. Meanwhile, Cohere continues to move forward in its competition with Cohere by raising $500 million.
Cohere Raises $500 Million While Taking on OpenAI
AI startup Cohere has raised $500 million in a funding round that values the company at over $5 billion, signalling its ambition to compete with industry leaders like OpenAI. However, Cohere cut around 20 employees the day after this funding round, which is about 5% of its total employees.
Harvey Secures $100 Million in Series C Funding
Harvey, an AI-powered legal technology startup, has secured $100 million in Series C funding at a $1.5 billion valuation, led by Google Ventures.
Harvey plans to use the new capital to expand its engineering and data capabilities, develop domain-specific models, and deepen partnerships with cloud and model providers to enhance its AI platform. We are curious how this will affect the company's spend with OpenAI, although since OpenAI is on the roster of the company's investors, the impact may be minor.
Cowbell Raises $60 Million Funding in Series C Funding
Cowbell, a leading AI-powered cyber insurance provider, has raised $60 million in Series C funding from Zurich Insurance Group, bringing its total funding to $160 million.