- GenAI360 - Weekly AI News
- Posts
- A Single CPU > IMO Gold Medalists, OpenAI & Adobe use YouTube & Midjourney data
A Single CPU > IMO Gold Medalists, OpenAI & Adobe use YouTube & Midjourney data
OpenAI might face a lawsuit from Google, Grok 1.5V > GPT-4V, Mistral 8x22B

Key Takeaways
This week’s key developments include:
Google and Meta introduced powerful new AI chips, while Intel introduced its new AI accelerator, which offers significant improvements over Nvidia’s models.
OpenAI could face a lawsuit from Google for allegedly using over one million hours of YouTube videos to train GPT-4, possibly violating YouTube’s terms of service, while Adobe used Midjourney for Firefly training.
X.ai’s Grok-1.5V multimodal model significantly advanced the understanding and processing of visual information.
A study by Anthropic measuring the persuasiveness of LLMs indicates that newer models can rival human persuasiveness.
Mistral released their new LLM, Mistral8x22B, which surpassed GPT-3.5 but still trails behind GPT-4 across various benchmarks.
The Latest AI News
This week has been another whirlwind for the AI world, with OpenAI and Adobe being sketchy about training data, models outperforming each other and IMO Olympic Medalists. Tech giants Google and Meta announce investments in AI chips, while Mistral and X.ai released new large models, and small language models are advancing once again.
AI Chips From Google and Meta, while Intel Introduces New AI Accelerator
The AI chip market has been rapidly growing with tech giants Google and Meta introducing their latest chips.
Announced at the Google Cloud Next Conference, Google launched Cloud TPU v5p, its latest AI chip that can train LLMs almost three times faster than its predecessor, TPU v4.
Meta also introduced its latest chip called Meta Training and Inference Accelerator (MTIA), a custom chip designed to boost the efficiency of training and inference for Meta’s ranking and recommendation models.
Moreover, the new MTIA chip aims to dramatically improve performance, supporting ranking algorithms and generative AI models like the LLaMa language models.
Intel unveiled its new AI accelerator called Gaudi 3, which delivers up to 50% better inference performance and 40% better power efficiency than Nvidia’s H100 at a lower cost.

Intel CEO Pat Gelsinger introduced Gaudi 3 at the Intel Vision event. (Source)
Open AI’s Use of YouTube Videos to Train GPT-4
Last week, we wondered if OpenAI were using YouTube videos to train its video generator Sora, as YouTube CEO Neal Mohan said this would be “an infraction of the platform’s terms and services.”
OpenAI has reportedly transcribed over one million hours of YouTube videos to train their flagship LLM, GPT-4. This goes against YouTube’s stated policy against such practices.
Mohan now mentioned that the terms of service “don’t allow for things like transcripts and video bits to be downloaded”. It’s also reported that President Greg Brockman was directly involved in collecting YouTube data for training purposes.
We could see some serious legal repercussions for OpenAI as Google can file a lawsuit. OpenAI and Google have yet to respond to the claims, so we’ll have to wait and see.
5% of Adobe’s Firefly Training Dataset was From Midjourney
On a similar note, Adobe’s AI image generator Firefly was trained using AI-generated images, including those from competitors like Midjourney. With 5% of Firefly’s training images being AI-generated images from other platforms, there are concerns around the ethical implications (while legal aspects of AI-generated images are yet to be defined).
To gain more training data, Adobe has also incentivized contributors by paying for images submitted to Firefly - even if those images are AI-generated.
Grok 1.5 Vision Introduced
X.ai’s Grok 1.5V is a first-generation multimodal model from Grok capable of processing a variety of visual information, such as:
Screenshots
Photographs
Documents
Diagrams
Charts
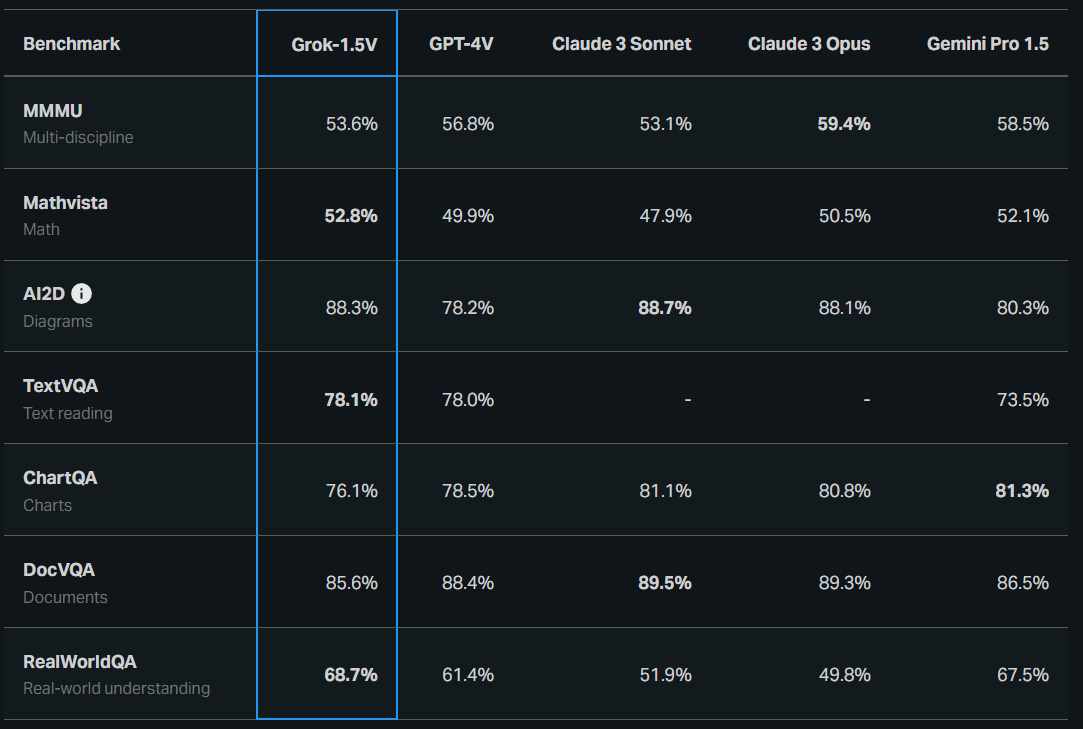
Benchmark comparison table of Grok-1.5V. (Source)
Grok 1.5V can keep up with or even exceed other leading multimodal models like GPT-4V across various existing benchmarks and introduces a new benchmark for real-world spatial understanding called RealWorldQA.
RealWorldQA assesses the model’s ability to understand real-world spatial scenarios through over 700 images with associated questions. It was released for community use.
X.ai provided a demonstration of Grok-1.5V translating a flowchart of a guessing game into executable Python code, which shows its practical application in coding from visual inputs.
Mistral’s New Model: Mixtral 8x22B
Mistral released its new model, Mixtral8x22B. It’s a new LLM with 176 billion parameters and a 65,000-token context window, aiming to surpass its predecessor and competitors like OpenAI’s GPT-3.5.
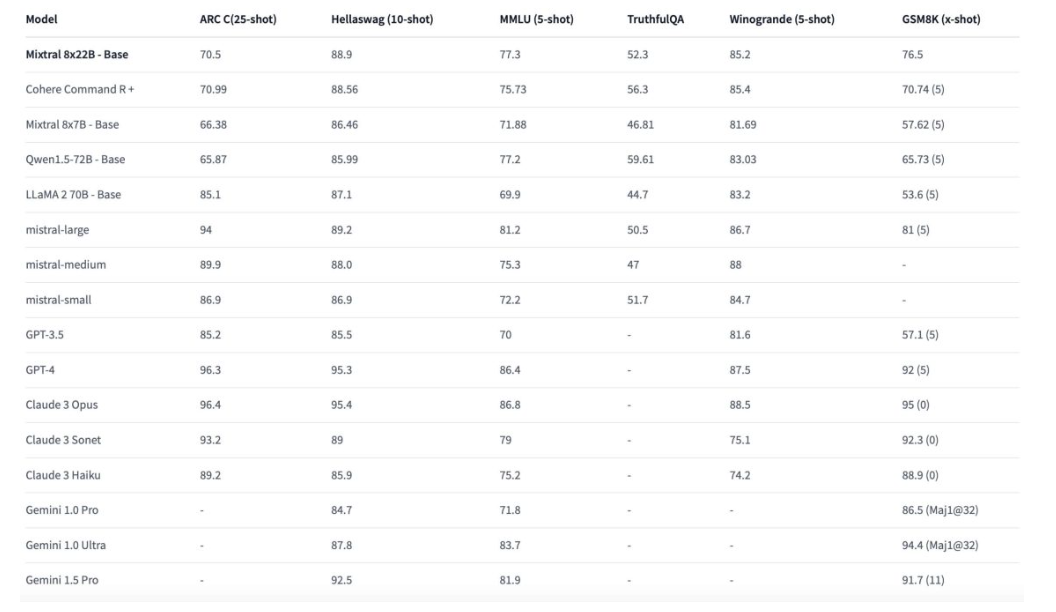
Mixtral 8x22B surpasses GPT-3.5 but falls short of GPT-4 in the benchmark comparison. (Source)
Mixtral is open-source, which helps democratize access to state-of-the-art LLMs since anyone can access and modify them. This new release coincides with other big LLM releases, including Google Gemini Pro 1.5 at Google Cloud Next and OpenAI’s GPT-4 Turbo.
AI Training Transparency Bill by Schiff
A new bill introduced by Congressman Adam Schiff requires AI companies to disclose copyrighted materials used in their training datasets to the Copyright Office before releasing AI systems.
It aims to balance AI's potential with the need for ethical guidelines and intellectual property protection, which has recently become controversial. We saw this in the legal challenges OpenAI faces from using YouTube videos to train GPT-4.
Advancements in AI Research
Anthropic provided an exciting perspective on how LLM persuasiveness is catching up to humans. Other advancements included a new solution to improve autonomous LLM safety and using smaller models that are cheaper to train as an alternative to larger models.
LLMs Persuasive as Humans?
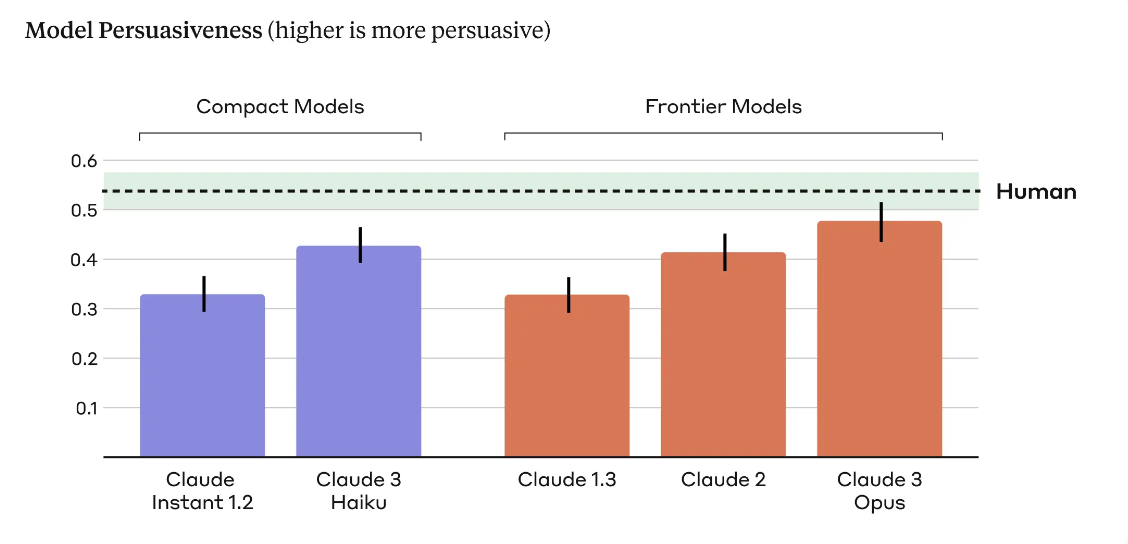
Accurately measuring the persuasiveness of AI-generated content has been tricky. There have been difficulties in generalizing laboratory findings to real-world scenarios where dynamic factors influence persuasion.
Anthropic’s new paper evaluates the persuasiveness of language models across different generations of its models and compares them to human-written arguments. It also highlighted that newer, larger models are more persuasive.
This was clear with the latest model, Claude 3 Opus, which was close to human persuasiveness in controlled experiments.
Reducing the Risk of Autonomous LLM Outputs
Safety and trust in autonomous LLMs that perform real-world actions without continuous human oversight is a big concern.
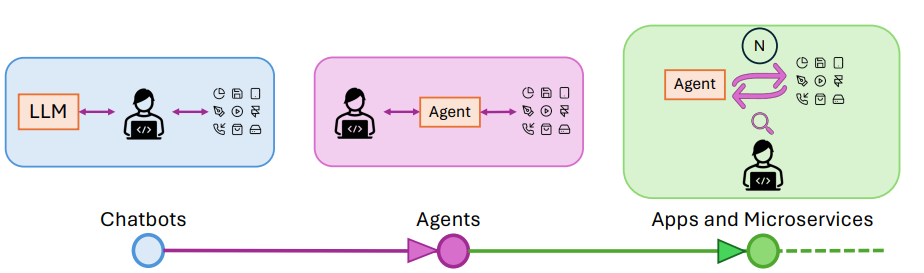
Evolution of LLMs from chatbots to apps and microservices. (Source)
This paper aims to tackle this issue by introducing the concept of “post-facto validation” for autonomous LLM applications. It focuses on validating actions after execution instead of before, which helps address the unpredictability and risk in autonomous LLM outputs.
It also proposes mechanisms like “undo” and “damage confinement” to mitigate risks from unintended actions.
The Gorilla Execution Engine (GoEX) is presented as a runtime solution that uses these concepts to make autonomous LLMs safer and more reliable to deploy.
A More Efficient Alternative to LLMs
Training and deploying LLMs with extensive parameter counts comes with a couple of problems - it’s inefficient and expensive.
A starting trend we're seeing after training our own small language model system for patent search and generation, we see others introducing new small language models (SLMs) with 1.2B and 2.4B that show performance comparable to larger models (7B-13B), making them an efficient alternative to current LLMs.
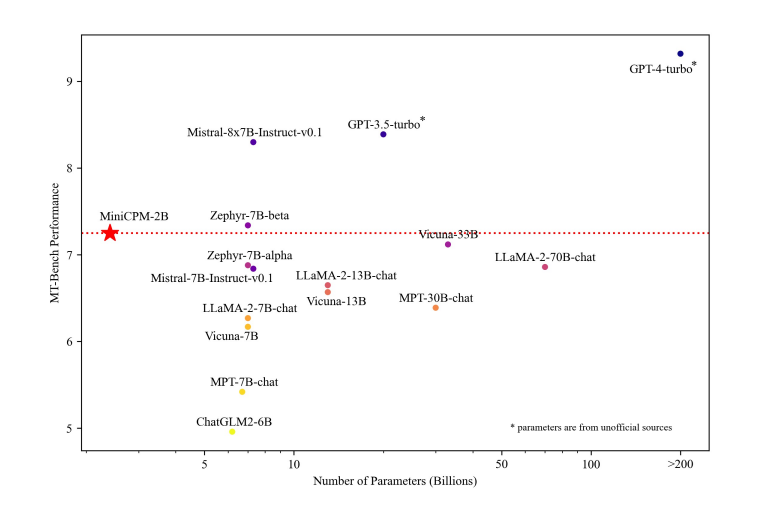
MiniCPM achieved a higher MTBench score than larger models. (Source)
It uses a scalable training strategy using a learning rate scheduler called Warmup-Stable-Decay, which boosts continuous training and domain adaptation. This reduces the need for extensive retraining.
Zero-shot Logical Querying on Any Knowledge Graph
Traditional complex logical query answering (CLQA) methods are limited to specific knowledge graphs (KGs) because they rely on relation embeddings. This means these methods struggle with generalization across different KGs.
This paper presents ULTRAQUERY, a model for zero-shot logical query reasoning on any KG. It uses an inductive approach with generalized projection and logical operators, allowing it to perform without retraining on new KGs.
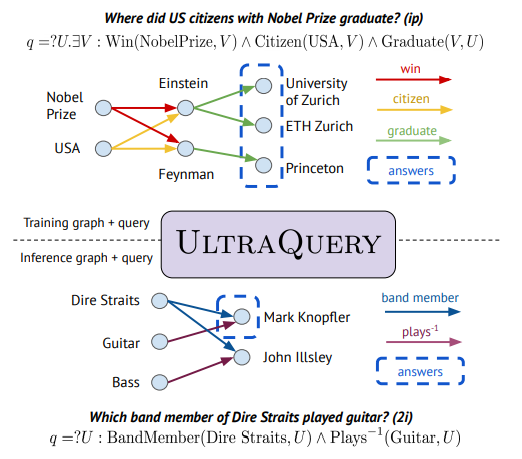
The proposed ULTRAQUERY method for query answering. (Source)
It also showed better or comparative performance to existing methods across various datasets.
Projects We Love
AI Pill Identifier: Multimodal RAG for Pill Search with FastSAM and YOLOv8
About 1 in 20 doses of medication are administered incorrectly - with the wrong medication taken. Can LLMs & Computer Vision fix it?
We've tested multiple advanced retrieval strategies offered by team LlamaIndex like Hybrid Retriever, Re-Ranking, BM25 Search, or QueryFusionRetriever (and combinations of those) to build a multi-modal RAG app to chat with your prescription pills!

Multimodal RAG for Pill Search Video
Some frameworks that caught our attention in the last week include:
FLEX: Enhances privacy in AI by allowing decentralized model training directly on local devices.
UltraEval: User-friendly evaluation framework for LLMs characterized by its lightweight design.
Patchscope: Helps interpret and explain the hidden representations within LLMs using their own language capabilities.
If you want your framework to be featured here, get in touch with us.
Conversations We Loved This Week
This week, we saw a couple of interesting debates, namely Karpathy’s discussion of deep learning issues and advancements in AI capabilities for solving complex mathematical problems.
Karpathy implements GPT-2 in C in 1000 lines of code and discusses Deep Learning issues
The code need to train LLMs, or frameworks like PyTorch consist of millions of lines of code across thousands of files due to abstractions like tensors, backpropagation, or deep learning layers. Andrej Karpathy reimplemented GPT-2 in about 1000 lines of C code, eliminating dependencies on large libraries by directly implementing the neural network training algorithm for GPT-2. This approach, while more brittle and demanding deep understanding of the training algorithms and meticulous coding, results in a simpler and more direct implementation. After the release got traction, he also discussed a few thoughts on the future of deep learning.
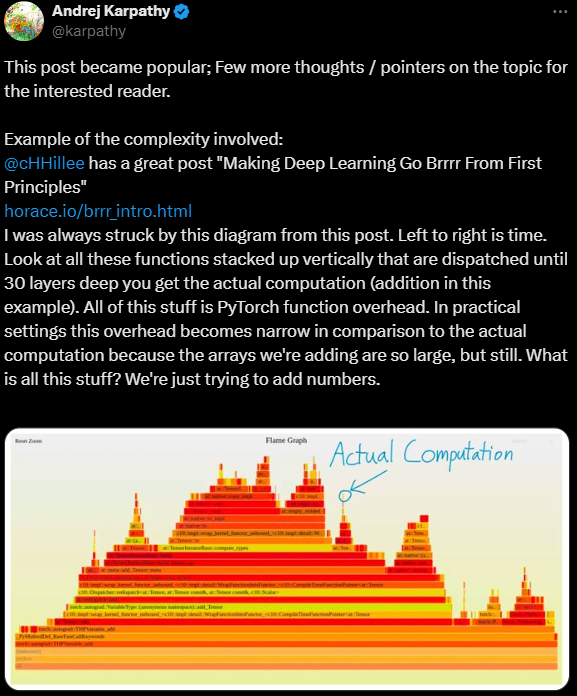
Karpathy’s take on PyTorch function overhead. (Source)
Andrej Karpathy discussed the intricacies and inefficiencies in modern deep learning practices. He looked at PyTorch in particular, explaining that the extensive function overhead delays computational tasks.
He also discussed the high startup latency that users experience - even for basic library imports. He proposed the potential of language models to evolve into compilers that could efficiently translate high-level programs into optimized code.
The conversation brought up some interesting real-world frustrations with current computational setups but also encouraged reflections on the trade-offs in programming and technology infrastructure between:
Speed
Security
Flexibility
Simplicity
Outperforming Human Silver & Gold Medalists

Sinha’s announcement on his new paper. (Source)
Shiven Sinha announced big advancements in solving geometry problems in the International Mathematical Olympiad (IMO).
Wu’s method successfully solved 15 out of 30 IMO geometry problems, which meant it outperformed other traditional methods. Combined with synthetic methods, the Wu Method solved 21 out of 30 problems—almost matching the performance of the AlphaGeometry system.
However, when Wu’s method was combined with AlphaGeometry, it could solve 27 out of 30 problems, which surpassed the performance of human IMO gold medalists.
We can see a massive advancement in AI’s ability to solve complex mathematical problems, pushing the boundaries of what automated systems can achieve. This also opens avenues for further research into combining different methodologies to improve AI's problem-solving capabilities.
Fundraising in AI
Collaborative Robotics, Terminus, and Cyera all successfully secured big funding rounds this week ($100 million or more), with Cyera securing the most at $300 million.
Collaborative Robotics Secured $100 Million in Series B Funding Round
Based in Santa Clara, Collaborative Robotics recently secured $100 million in a Series B funding round led by General Catalyst. This funding boost supports their development of “cobots” (practical collaborative robots), designed to help humans in industries like manufacturing and healthcare.
Terminus Secured $276 Million in Series D Funding Round
Terminus, a Beijing-based AI firm, secured $276 million in Series D funding led by AL Capital. The investment will support the development and global expansion of Artificial Intelligence of Things (AIoT) technologies and LLMs.
Cyera Raised $300 Million in Series C Funding Round
Cyera, a startup leveraging AI for data management within networks, has raised $300 million in a Series C round, pushing its valuation to $1.4 billion. The funds will help Cyera with its data security technology development processes.