- GenAI360 - Weekly AI News
- Posts
- 🍓 in Fall, Magic's 100M Context, Alexa + Claude = ❤️
🍓 in Fall, Magic's 100M Context, Alexa + Claude = ❤️
Plus, Announcing RetrieveX Conference Tickets & Discount

Before we start, share last week's news with a friend or a colleague:
Key Takeaways
OpenAI's Project Strawberry, set for potential release in fall 2024, aims to drastically advance AI reasoning capabilities and address current limitations of GPT-4, including complex multi-step problems and hallucinations.
Magic developed LTM (Long-Term Memory) models capable of reasoning on up to 100M tokens of context during inference, equivalent to about 10 million lines of code or 750 novels.
Jina AI revealed a "modality gap" in multimodal AI models, where text embeddings and image embeddings cluster in separate parts of the semantic space.
Nvidia released Eagle, a family of vision-centric high-resolution multimodal LLMs that uses a channel-concatenation-based fusion and showed impressive performance on various multimodal benchmarks like GQA and MMMU.
Google DeepMind used weaker but cheaper models for generating synthetic training data, achieving up to 31.6% relative gains compared to strong but expensive (SE) models.
Got forwarded this newsletter? Subscribe below👇
Announcing RetrieveX Conference on Oct 17 in San Francisco. 25% OFF For the Next 3 Days
Executive in GenAI? Join RetrieveX, the top conference in retrieval for GenAI. Exclusively for those building high-accuracy, multimodal workflows, featuring leaders from Microsoft AI, YC, Bayer Radiology, Matterport, Cresta, as well as the creators of PyTorch and KubeFlow.
Checkout with promo code LABORDAY25 for 25% off (valid for the next three days). Prices are going up by end of week, so secure your spot sooner rather than latter.
Date: October 17, 10:30am - 7pm PT
Venue: The Midway, 900 Marin St, San Francisco
Attendees: 300 AI executives
The Latest AI News
There were quite a few model releases, ranging from SLMs to text-to-image models. Moreover, a chatbot arena update saw Grok-2 ranked very highly, which means xAI might take the top spot very soon.
Not to mention that we heard some news about Project Strawberry and that OpenAI is struggling to keep up with expenses (despite having 200 million users) due to inference costs. There are currently talks for a new funding round that would put them at over $100 billion valuation.
Moreover, OpenAI and Apple are set to collaborate for Siri (but not in Europe), and Amazon is planning a similar play with Anthropic by releasing a (subscription) version of Alexa that is powered by Claude. AI is the new streaming, folks.
OpenAI’s Project Strawberry Might Release in Fall, Struggles With Expenses Despite Potential Funding Round, and California Bill SB 1047 Passed

We might see Project Strawberry release relatively soon. (Source)
Project Strawberry is reportedly set for a potential release in fall 2024. As we talked about before, Strawberry has been rumored to drastically advance AI reasoning capabilities and even address the current limitations of GPT-4.
This includes issues like complex, multi-step problems and hallucinations that have posed problems for GPT-4 in the past.
OpenAI needs Watermelon Strawberry sugar, badly.
With 200 million MAUs, OpenAI faces inferencing costs. In 2024, the company is projected to incur expenses of approximately $8.5 billion. This is largely thanks to Microsoft's pricing structure, which charges OpenAI about $10.30 per hour for an eight-GPU server, compared to higher public rates (this still is… $4B). Simultaneously, new models are creeping up in terms of accuracy (hello, 350M+ lifetime downloads of Llama 3.1). Hence, OpenAI needs just to put out something impressive that would blow out the competition out of water, OR raise another funding round to cover the costs of compute.
I guess, Sam Altman plans to do both, with the next funding round might put them at $100 billion, with Nvidia and Apple in talks to be a part of it.
California Bill SB 1047 & AB 3211
Meanwhile, California bill SB 1047 was passed. It’s a bill designed to prevent “disasters” caused by AI systems before they occur. This refers to serious events that would cause global issues, like using AI to cause a cyberattack that would result in more than $500 million in damages.
Although, it wouldn’t apply to every AI model - only the ones that are considered large enough like GPT-4. The bill was supported by Musk, who has been vocal about how the potential dangers of AI need to be monitored, despite the fact that xAI would also be affected by the bill’s requirements.
Additionally, OpenAI, Adobe, and Microsoft have expressed support for another California bill called AB 3211. It requires tech companies to label AI-generated content. This support is evidenced by letters from the companies viewed by TechCrunch, marking a shift from their previous opposition.
AB 3211 mandates watermarks in the metadata of AI-generated photos, videos, and audio clips. While many AI companies already implement this practice, the bill goes further by requiring large online platforms like Instagram or X to label AI-generated content in a way that’s easily understandable to average viewers.
Magic’s 100 Million Context Window and Nvidia’s Eagle

Current long context evals like Needle In A Haystack have various limitations. (Source)
Magic has developed LTM (Long-Term Memory) models capable of reasoning on up to 100M tokens of context during inference, equivalent to about 10 million lines of code or 750 novels. Their LTM-2-mini model is significantly more efficient in computation and memory usage compared to traditional models like Llama 3.1 405B.
They also introduced HashHop, a new evaluation method for long-context models that eliminates semantic hints and requires models to store and retrieve maximum information content, addressing flaws in current evaluation techniques like Needle In A Haystack.
Eagle was another release we saw - a family of vision-centric high-resolution multimodal LLMs that uses a channel-concatenation-based fusion. The models support input resolutions up to over 1000 pixels and perform strongly on multimodal benchmarks, especially resolution-sensitive tasks like OCR and document understanding.
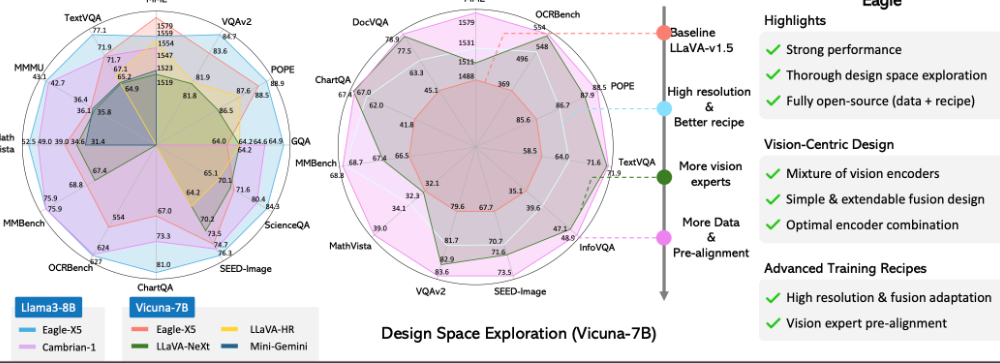
Eagle showed impressive performance on multimodal benchmarks. (Source)
The Eagle family includes multiple variants such as Eagle-X4 and Eagle-X5 models with 7B and 13B parameters, built on Vicuna language models and LLaVA-v1.5 pretraining.
The project is actively developing, with plans for models trained on larger and more diverse datasets, evaluation code, and vision encoder model weights with pre-alignment. An online demo of Eagle-X5-13B-Chat is available, and the project has achieved recognition, winning 2nd place in a CVPR24 Challenge on Driving with Language.
New TRL Update Released
The TRL v0.10.1 update just dropped with some pretty b
One of which is that models can now be trained with DeepMind’s Online DPO. It’s an alignment method called OnlineDPO that generates data on the fly, eliminates the need for pre-collected preference datasets, and yields better results than traditional DPO.
It also added support to align vision-language models (LLaVa-1.5, PaliGemma, and Idefics2) with DPO. DPO was previously used for text-only language models, so this update means DPO can now be applied to vision-language models as well.
The update allows for the integration of Ligon Triton kernels, which leads to lower memory usage and faster throughput in training. This might allow for training larger models or using smaller hardware.
OpenAI and Patched Collaborate on Static Analysis Evaluation Benchmark
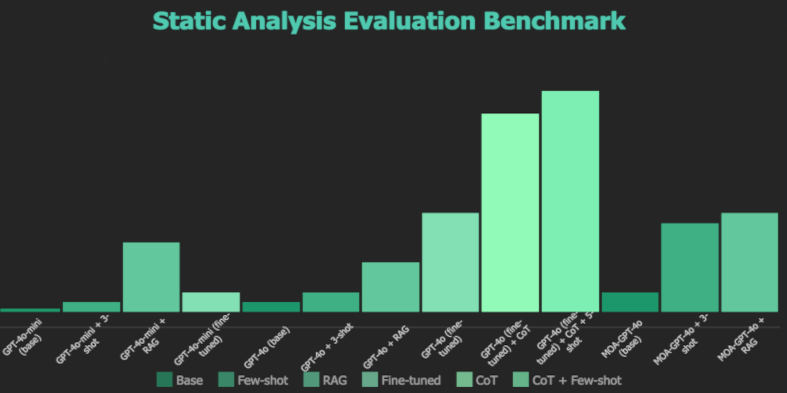
How various models performed on the Static Analysis Evaluation benchmark. (Source)
OpenAI collaborated with Patched to fine-tune GPT-4o for the Static Analysis Evaluation Benchmark. It’s designed to assess LLMs' performance in fixing software vulnerabilities. The new version features more challenging instances with larger sample sizes (512-1024 tokens) and increased difficulty.
The benchmark methodology involved:
Scanning top Python repositories on GitHub
Filtering for file size
Verifying vulnerabilities using Semgrep
Curating a dataset representing real-world vulnerabilities in popular open-source projects
Results show that combining techniques like few-shot prompting, RAG, and fine-tuning leads to improved performance. Fine-tuned models consistently outperform base models, and larger models generally perform better.
IBM Cloud Becomes First Cloud Customer for Gaudi AI and Cerebras’ New AI Processor

IBM Cloud is the first cloud customer for Gaudi AI. (Source)
Although Softbank ended its partnership with Intel recently, Intel secured IBM Cloud as its first cloud customer for the Gaudi 3 AI accelerator chip. IBM Cloud will offer Gaudi 3 to customers in early 2025 for both hybrid and on-premise environments, and plans to support Gaudi 3 within its Watsonx AI and data platform.
Intel's expectations for Gaudi 3 revenue in 2024 are modest at $500 million, significantly lower than AMD's projected $4.5 billion from its Instinct MI300-series GPUs and Nvidia's expected $40 billion from its data center business. Despite Gaudi 3's high performance-per-dollar, Intel faces challenges in attracting customers away from Nvidia.
Nvidia's upcoming Blackwell chip, set for production ramp-up in Q4, poses a significant threat to Intel's Gaudi 3. Blackwell is expected to offer up to four times the performance of the H100, the chip Gaudi 3 is currently compared against, potentially further challenging Intel's position in the AI chip market.
A new AI processor was also introduced by Cerebras. They developed the Wafer-Scale Engine-3 (WSE-3), which they claim is the world's largest and fastest AI processor. This powers their CS-3 system, a new class of AI supercomputer designed for generative AI training and inference with exceptional performance and scalability.
CS-3 systems can be quickly clustered to create some of the world's largest AI supercomputers, simplifying the process of deploying and running very large AI models. This makes it easier for organizations to work with cutting-edge AI at scale.
Amazon Hires Covariant Founders and Aims to Release New Version of Alexa Powered by Claude
Amazon has hired the founders of AI robotics startup Covariant - Pieter Abbeel, Peter Chen, and Rocky Duan. They also hired approximately 25% of the company's employees.
As part of the deal, Amazon has secured a non-exclusive license to use Covariant's robotic foundation models, which are described as "a large language model, but for robot language." These models focus on enabling robotic arms to perform common warehouse tasks like bin picking.
Amazon plans to integrate Covariant's AI technology into its existing robot fleet to improve performance and create value for customers. This aligns with Amazon's ongoing efforts to enhance its fulfillment and robotics technologies.
The deal structure seems similar to the ones we saw a few months ago when Amazon hired most of Adept’s top employees.
Amazon also plans to release a revamped version of Alexa in October, primarily powered by Anthropic's Claude AI models rather than Amazon's own AI. This decision was made after initial versions using Amazon's in-house software struggled with response times and coherence.
The new "Remarkable" Alexa will be a paid service, costing between $5 to $10 per month, while the current "Classic" Alexa will remain free. Amazon hopes this new version will help generate revenue from the currently unprofitable Alexa division.
The upgraded Alexa is designed to handle more complex queries, carry on conversations that build on prior interactions, provide shopping advice, aggregate news, and perform more complicated tasks like ordering food or drafting emails from a single prompt.
Advancements in AI Research
While we saw some multimodal releases like Eagle and Phi-3 Vision, researchers also introduced a new family of VLMs in a new paper. DeepMind looked into ways of generating high-quality synthetic data.
Another paper that caught our eye was about the law of next-token predictions, since the black-box nature of LLMs makes it difficult to understand how the model reached its conclusions.
How Cheaper Models Outperform More Expensive Ones

Language models being fine-tuned with Gemma 2 and Gemini 1.5 data. (Source)
DeepMind decided to challenge the conventional wisdom of using strong but expensive (SE) language models for generating synthetic training data. They investigated whether using weaker but cheaper (WC) models could be more compute-optimal for training LLM reasoners.
They conducted extensive experiments comparing data generated from WC and SE models across three key metrics: coverage, diversity, and false positive rate. They then fine-tuned models on this data in various setups, including knowledge distillation, self-improvement, and a novel "weak-to-strong improvement" paradigm.
Models trained on WC-generated data consistently outperformed those trained on SE-generated data across multiple benchmarks, with relative gains of up to 31.6%. For example, using Gemma2-9B (WC) data instead of Gemma2-27B (SE) data led to 6% higher performance in knowledge distillation and 5.8% in weak-to-strong improvement for math reasoning tasks.
LLMs in Sales and Negotiation: Simulating Human-Like Persuasion
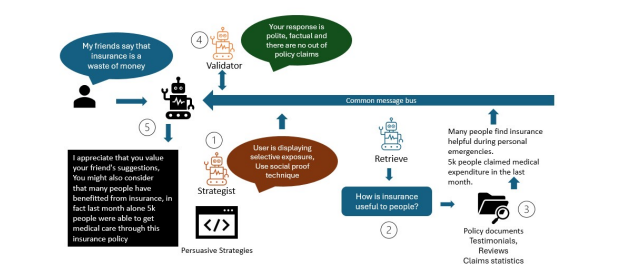
Example workflow of an insurance bot. (Source)
Researchers developed a multi-agent framework to study the persuasion capabilities of LLMs various domains such as insurance, banking, and retail. This work addresses the challenge of creating AI systems that can engage in persuasive dialogue while dynamically adapting to user resistance and personality types.
A collaborative approach using multiple AI agents was used, which included:
A primary conversational agent
Auxiliary agents for information retrieval and analysis
A fact-checking component
They simulated conversations using LLM-generated personas with varying demographics and emotional states, and measured persuasion effectiveness through pre- and post-interaction surveys, as well as user decisions.
The paper showed that LLMs are capable of both persuading and resisting persuasion effectively. The AI agents demonstrated the ability to create perspective changes in users and influence purchase decisions. That sounds promising, but further work still needs to be done as conversations were terminated due to inadequate information from the sales agent.
The Universal Law of LLM Learning
Researchers from the University of Rochester and the University of Pennsylvania have discovered a precise and quantitative law governing how LLMs learn contextualized token embeddings for next-token prediction. In particular, this paper looks at the issue of understanding the internal data processing mechanisms of LLMs, which have long been considered black boxes.
They used a wide range of open-source LLMs, including GPT variants, Llama models, and newer architectures like RWKV and Mamba. They also introduced a metric called "prediction residual" (PR) to quantify an LLM's next-token prediction capability at each layer.
What came from the results is a universal "law of equi-learning", where each layer contributes equally to enhancing prediction accuracy, from the lowest to the highest layer. The law emerged consistently across various model architectures, sizes, and pre-training data.
Text2SQL: Unifying AI and Databases With TAG
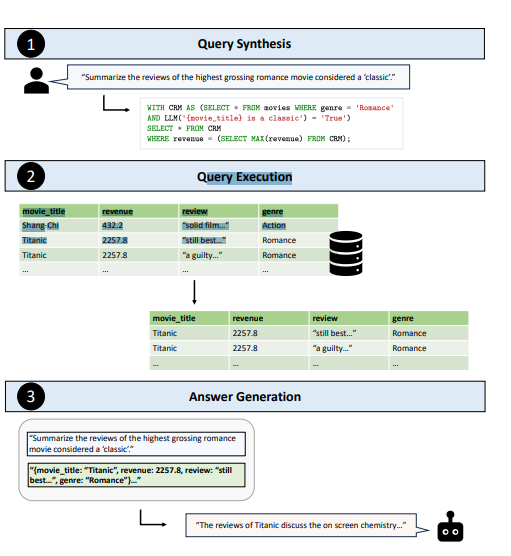
The three stages of the TAG pipeline. (Source)
Researchers from UC Berkeley and Stanford University have introduced a new paradigm called Table-Augmented Generation (TAG) to address the limitations of current Text2SQL and RAG methods. This work tackles the challenge of answering complex natural language questions over databases that require both world knowledge and semantic reasoning.
They developed a unified framework that combines the strengths of language models (LMs) and database systems. TAG consists of three key steps:
Query synthesis: Translating natural language requests into executable database queries
Query execution: Efficiently computing relevant data using database systems
Answer generation: Utilizing LMs to generate final natural language answers
To evaluate TAG, they created a dataset, requiring either world knowledge or semantic reasoning. Afterwards, they compared TAG against several baselines, including traditional Text2SQL and RAG approaches.
Results show hand-written TAG pipelines consistently achieved 40% or better exact match accuracy, significantly outperforming all other baselines which failed to exceed 20% accuracy. TAG demonstrated particular strength in comparison queries, with up to 65% accuracy.
Frameworks We Love
Some frameworks that caught our attention include:
SAM2POINT: Adapts the SAM2 for zero-shot and promptable 3D segmentation by interpreting 3D data as multi-directional videos
OmniRe: Comprehensive 3D Gaussian Splatting framework that reconstructs high-fidelity dynamic urban scenes from on-device driving logs,
GradBias: Uses a combination of LLMs, Text-to-Image generative models, and Vision Question Answering to detect, quantify, and explain biases in image generation.
If you want your framework to be featured here, reply to this email and say hi :)
Conversations We Loved
One discussion about the modality gap in multimodal modals was also certainly one to look at since we don’t see this being talked about too often. In addition, a post about applying HybridRAG to financial document analysis makes us wonder how we might see this new approach be applied to other domains.
Exploring the Modality Gap in Multimodal AI

Jina AI’s discussion about the modality gap. (Source)
Jira posted an interesting exploration of the "modality gap" in multimodal AI models, particularly those using CLIP (Contrastive Language-Image Pretraining). The discussion, centered around research by Jina AI, reveals an unexpected quirk in how these models process and relate text and images.
At first glance, you might assume that a well-trained AI would treat a picture of an apple and the text "an apple" as nearly identical. But surprisingly, that's not the case. The research shows these models tend to cluster text embeddings and image embeddings in separate parts of their semantic space, creating a "gap" between modalities.
What's also interesting is how this gap emerges unintentionally. The models are encoding not just the semantic content, but also the medium itself. This happens even after extensive training, so it might be a fundamental aspect of how these models learn to represent information.
Overcoming the Limitations of KG and Vector-Based RAG

AI engineer Rohan Paul brought up the potential of HybridRAG. (Source)
A new approach called HybridRAG is making waves in the field of financial document analysis, combining KG and vector-based RAG.
Financial documents are notoriously difficult for AI systems to parse because of their specialized terminology and intricate formats. Instead, HybridRAG gets the best of both worlds from Knowledge Graph and Vector-based RAG for more comprehensive and accurate information retrieval.
Note that while this paper is focusing on financial document analysis, there’s definitely potential for HybridRAG to be used for other applications because of its ability to excel at both extractive and abstractive questions.
You might be thinking that this sounds great on paper, but does it actually perform well? The answer is yes - HybridRAG outperformed both VectorRAG and GraphRAG across various metrics. As a result, we might see HybridRAG be applied to other domains with complex information structures like legal documents or medical records.
Money Moving in AI
We saw the success of three funding rounds for Story, Cursor, and Defcon - all of which were under $100 million. Interestingly, each company focuses on pretty different applications in AI: Story in blockchain, Cursor in coding, and Defcon in military logistics.
Aside from Magic’s LTM models, they succeeded in raising $320 million in a funding round. Another AI coding business called Codeium also secured funding through a series C round for $150 million.
Magic Raises $320 Million
Magic, secured a massive $320 million funding round led by ex-Google CEO Eric Schmidt, with participation from Alphabet's CapitalG and Atlassian.
They also announced that they will work with Google Cloud to build two supercomputers that will use Nvidia’s H100 GPUs and Blackwell chips.
Codeium raises $150 million in Series C Funding Round
Codeium, an AI-powered coding assistant startup competing with GitHub Copilot, has secured a $150 million Series C round led by General Catalyst, valuing the company at $1.25 billion.
This latest investment brings Codeium's total funding to $243 million just three years after its launch, with the company achieving unicorn status and growing its user base to over 700,000 developers and 1,000 enterprise customers.
Story Raises $80 Million in Series B Funding Round
Story, a startup building a blockchain-based platform for IP tracking and monetization in the age of AI, has secured $80 million in Series B funding led by Andreessen Horowitz's crypto division, with participation from Polychain Capital and other notable investors. The round values Story at $2.25 billion post-money and brings its total funding to $143 million.