- GenAI360 - Weekly AI News
- Posts
- August in AI: Grok-2 > GPT-4 Turbo, New SOTA for Text-to-Image & Video Gen
August in AI: Grok-2 > GPT-4 Turbo, New SOTA for Text-to-Image & Video Gen
Plus, SLMs from NVIDIA, MSFT, Google
In a new experiment, we decided to provide a monthly mega-roundup of all things that may have flown under the radar for you in August. Before we start, share last week's news with a friend or a colleague:
Join RetrieveX Conference on Oct 17 in San Francisco. 30% OFF Before Prices Go Up Tomorrow
Join RetrieveX, our flagship conference in retrieval for GenAI. Exclusively for those building high-accuracy, multimodal workflows, featuring leaders from Meta AI, Microsoft AI, YC, Bayer Radiology, Matterport, Cresta, as well as the co-creators of Meta LLama, PyTorch, Chameleon, and KubeFlow.
Checkout with promo code FINALCALL for 30% off (before the prices increase from $649 to $949 tomorrow). Prices are going up by end of week, so secure your spot sooner rather than latter.
Date: October 17, 10:30am - 7pm PT
Venue: The Midway, 900 Marin St, San Francisco
Attendees: 300 AI executives
Key Takeaways for August
Hermes 3 by Nous Research showed significant improvements over its predecessor, demonstrating competitive benchmark scores against Llama 3.1 through enhanced training techniques.
Ideogram 2.0, a SOTA text-to-image model, is now freely available with enhanced features and styles, improving image quality and text rendering through advanced training methods.
Google AI Edge's MediaPipe enabled running 7B+ parameter language models in browsers using WebAssembly and WebGPU, overcoming memory restrictions through redesigned model-loading code.
Researchers developed Pyramid Attention Broadcast (PAB) for real-time video generation, achieving up to 20.6 FPS with a 10.5× acceleration by mitigating redundancy in attention computations.
Google DeepMind open-sourced the Vizier algorithm, outperforming industry baselines in black-box optimization through a Gaussian process bandit approach.
Anthropic’s new prompt caching feature dramatically reduces costs and latency for long prompts, set to become an industry norm.
Huawei challenges Nvidia with the Ascend 910C AI chip, targeting the Chinese market amid production difficulties due to U.S. sanctions.
Grok-2 and Grok-2 mini outperformed GPT-4 Turbo in benchmarks such as GPQA and MMMU, excelling in reasoning and factual accuracy.
DeepSeek-Prover-V1.5 is an advanced theorem-proving LLM with improved performance on formal mathematics tasks, showcasing state-of-the-art results on rigorous benchmarks like ProofNet.
Got forwarded this newsletter? Subscribe below👇
The Latest AI News
Things seemed to have taken a strange turn regarding the Strawberry situation. Meanwhile, some neat optimization frameworks and libraries were introduced, along with a bunch of language and image generator models.
There were quite a few model releases, ranging from SLMs to text-to-image models. Moreover, a chatbot arena update saw Grok-2 ranked very highly, which means xAI might take the top spot very soon.
Salesforce, Jamba, and Hermes Expand the AI Model Landscape
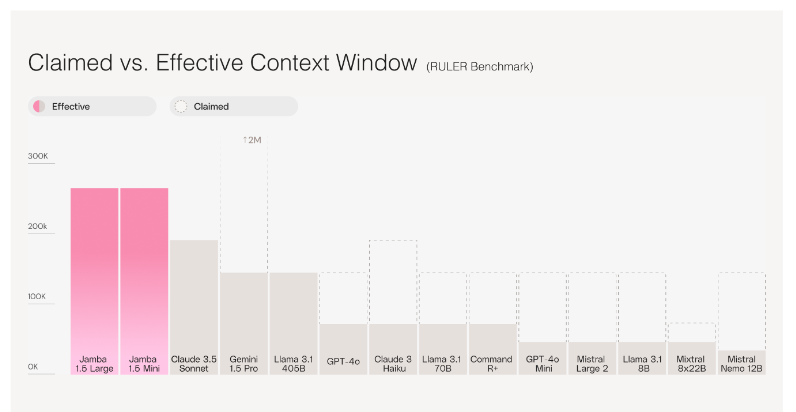
Comparison of claimed vs effective context window for the RULER benchmark. (Source)
Salesforce announced the release of Einstein SDR Agent and Einstein Sales Coach Agent. Einstein autonomously manages inbound leads by answering questions, handling objections, and scheduling meetings, all while grounded in a company’s CRM and external data.
On the other hand, Einstein Sales Coach Agent does exactly what you’d expect from the name - coach sellers via role-plays and provide personalized feedback afterwards.
What’s more is that these AI agents can be tailored to a company’s specific needs, including setting engagement guardrails and language preferences, making them highly adaptable to different sales strategies. We’re seeing companies like Accenture use them to improve deal effectiveness and scale support for more complex sales activities.
Another release included AI21 Labs’ Jamba 1.5 Mini and Large models, built on the novel SSM-Transformer architecture. These offer superior long-context handling, speed, and quality. These models are the first non-Transformer models to match the performance of leading competitors, featuring a 256K context window—the longest in the market for open models.
The Jamba 1.5 models are designed for resource efficiency, capable of handling up to 140K tokens on a single GPU for Jamba 1.5 Mini.
In particular, these models stand out because they maintain high performance across the entire context window, significantly improving the efficiency and accuracy of enterprise-scale applications. Independent tests showed Jamba 1.5 Mini as the fastest model on 10K contexts, outpacing other models in its size class.
Hermes 3 by Nous Research was also a noteworthy release with drastic improvements over its predecessor, Hermes 2. Some of which include:
More reliable function calling
Better code generation skills
Enhanced general assistant capabilities
In terms of benchmark performance, Hermes 3 is certainly no slouch as it showed highly competitive benchmark scores with Llama 3.1.
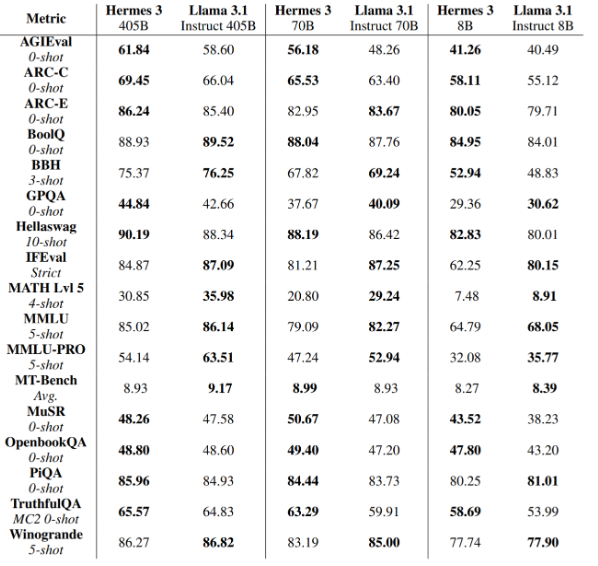
Hermes 3 was able to outperform Llama 3.1 on benchmarks like AGIEval and ARC-C. (Source)
Ideogram’s New Model and FLUX Available on 3 Platforms

Sample image produced by Ideogram 2.0. (Source)
Ideogram 2.0, a SOTA text-to-image model, is now accessible to all users via Ideogram.ai and a newly launched iOS app. The platform also introduces premium features through subscription plans, offering enhanced creative control and flexibility.
The model supports various styles such as realistic and design, so users can create highly detailed and context-specific images. These styles boost the realism of textures and accuracy of text in designs.
Improvements over its predecessor include creative tools like Magic Prompt and Describe, which help users generate and refine prompts for image creation. These tools enhance the iterative creative process, allowing for continuous reimagining of visual concepts.
We mentioned before that Midjourney had some serious competition with Black Forest Labs’ FLUX-1 models. Turns out these models are available on three platforms:
Google, Nvidia, and Microsoft Advance SLMs
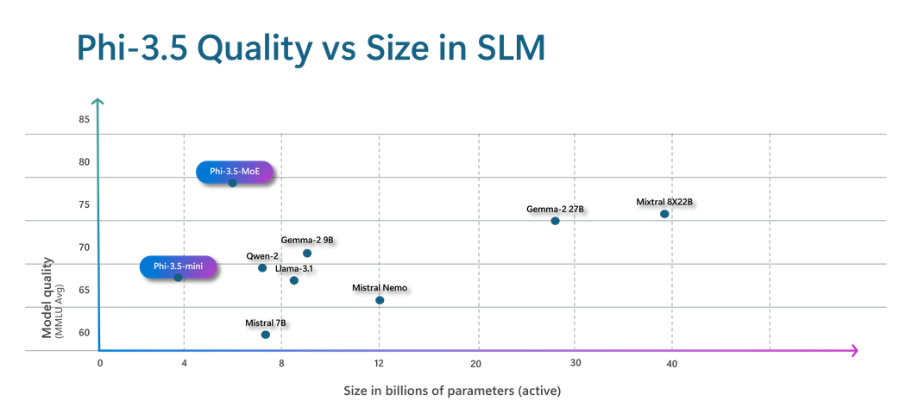
Phi 3.5-MoE showed impressive modal quality on the MMLU benchmark. (Source)
Given the recent trend of the rising popularity of SLMs recently, it isn’t too surprising to see more SLM releases.
Google AI Edge's MediaPipe redesigned its model-loading code to overcome memory restrictions, which means larger language models (7B+ parameters) can be run in the browser using their cross-platform inference framework.
The framework compiles C++ code into WebAssembly for efficient browser performance while leveraging WebGPU API for direct GPU access. New strategies, such as asynchronous layer loading and local caching, drastically reduced WebAssembly memory usage, so larger models can run smoothly.
After Nvidia discussed how to prune Llama-3.1 8B to Llama-3.1-Minitron-8B, they released Mistral-NeMo-Minitron 8B. It’s a miniaturized version of the Mistral NeMo 12B model, which delivers SOTA accuracy in a compact 8 billion parameter form factor.
Mistral-NeMo-Minitron 8B leads on nine popular benchmarks for language models of its size, covering tasks like language understanding, reasoning, summarization, coding, and generating truthful answers.
NVIDIA also announced Nemotron-Mini-4B-Instruct, another SLM optimized for low memory usage and faster response times on NVIDIA GeForce RTX AI PCs and laptops, available as part of NVIDIA ACE technologies.
Meanwhile, Microsoft introduced Phi-3.5, an updated family of SLMs including:
Phi-3.5-mini (3.8B parameters)
Phi-3.5-vision
Phi-3.5-MoE (Mixture-of-Experts with 42B total parameters but only 6.6B active).
Phi-3.5-mini enhances multi-lingual support with a 128K context length, showing significant improvements in languages like Arabic, Dutch, Finnish, Polish, Thai and Ukrainian with 25-50% performance boosts.
Phi-3.5-MoE outperforms larger dense models in quality and performance, supporting over 20 languages and employing robust safety post-training strategies combining Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
Things seemed to have taken a strange turn regarding the Strawberry situation. Meanwhile, some neat optimization frameworks and libraries were introduced, along with a bunch of language and image generator models.
AI Optimization Trifecta: LLM Compressor, Apple’s ToolSandbox, and PyTorch’s FlexAttention
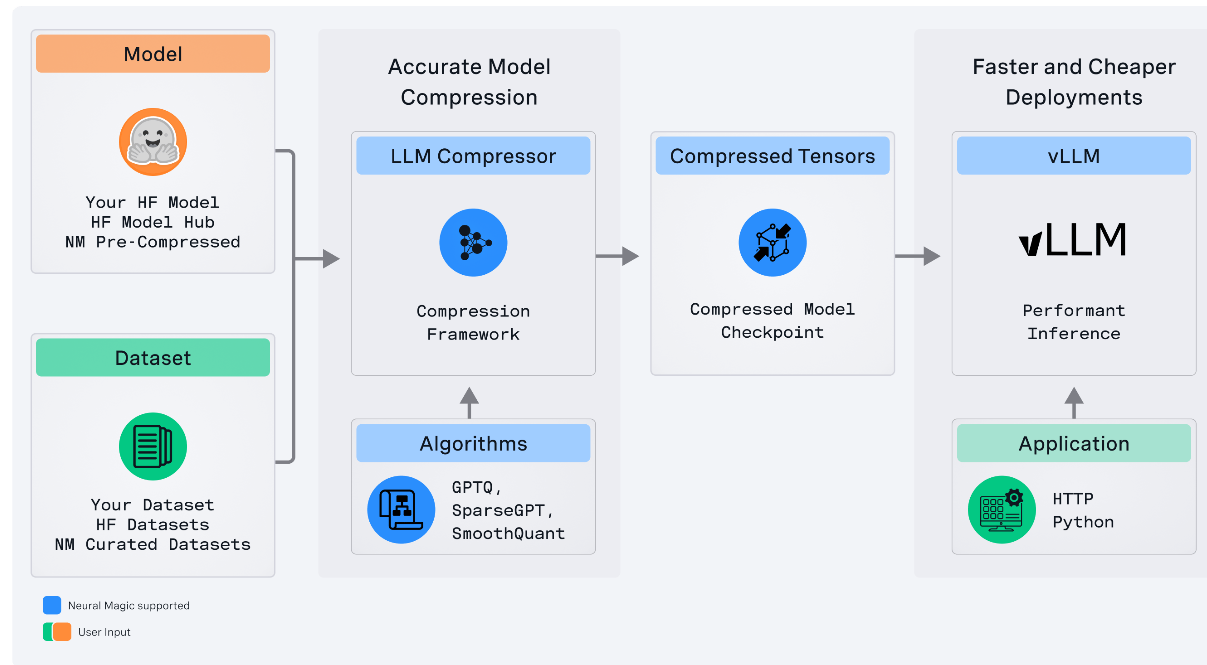
LLM compressor overview. (Source)
NeuralMagic’s LLM Compressor is a unified library for creating compressed models for faster inference with vLLM. It enables various compression techniques like weight quantization, activation quantization, and pruning.
We saw that Llama 3 was adapted to multimodality. NeuralMagic also did some work with Llama 3 by using LLM Compressor to create fully quantized versions of Llama 3.1.
It also integrates seamlessly with Hugging Face models and vLLM, which makes deployment pretty straightforward. LLM Compressor showed notable performance improvements, with INT8 weight and activation quantized models showing up to 1.6x speedup compared to FP16 baselines at low query rates.
ToolSandbox is a new evaluation framework for assessing tool-use capabilities of LLMs, addressing limitations of previous evaluation methods. It introduces stateful tool execution and implicit state dependencies between tools, moving beyond simple stateless web services or single-turn prompts.
The framework includes a built-in user simulator that enables on-policy conversational evaluation, allowing for more dynamic and realistic testing scenarios. ToolSandbox implements a dynamic evaluation strategy that can assess both intermediate and final milestones over arbitrary interaction trajectories.
Optimization news continued with FlexAttention, a new PyTorch API that allows implementing many attention variants in a few lines of idiomatic PyTorch code, addressing the lack of flexibility in existing optimized attention implementations.
It introduces a flexible API with a user-defined score_mod function that can modify attention scores prior to softmax, which enables various attention patterns like:
Causal masking
Relative positional encodings
Sliding window attention
FlexAttention uses torch.compile to lower the user-defined functions into a fused FlashAttention kernel, achieving performance competitive with handwritten kernels without materializing extra memory.
Llama 3 Pruning and Claude's Caching Technique
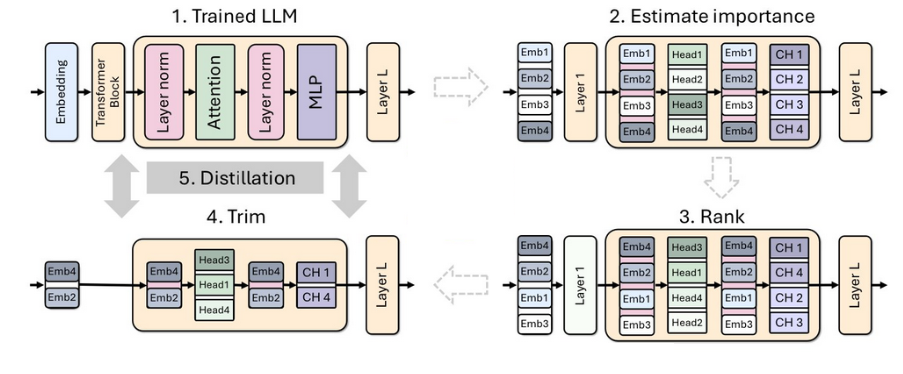
Pruning and distillation process of a single model. (Source)
We’ve seen how small language models are recently attracting attention with various releases such as GPT-4 mini and Gemma 2 2B. Nvidia is continuing the SLM momentum by showing us how larger models can be pruned to obtain a smaller model, using Llama-3.1-Minitron-4B as an example. This involves structured weight pruning combined with knowledge distillation.
The pruning process includes both depth pruning (removing 16 layers) and width pruning (reducing embedding and MLP dimensions).
Knowledge distillation is used to retrain the pruned model, with the original 8B model serving as the teacher. The pruned and distilled 4B model outperforms other models of similar size on various benchmarks, while requiring fewer training tokens and compute resources compared to training from scratch.
Anthropic has introduced prompt caching for its Claude AI models, letting developers store and reuse large amounts of context between API calls. This feature is currently available in public beta for Claude 3.5 Sonnet and Claude 3 Haiku, with support for Claude 3 Opus coming soon.
Prompt caching can reduce costs by up to 90% and latency by up to 85% for long prompts. It's particularly useful for scenarios like conversational agents, coding assistants, large document processing, and agentic search where repeated access to extensive context is needed.
The pricing model for cached prompts involves a 25% premium over base input token prices for writing to the cache, but only 10% of the base price for reading cached content. This structure makes it appealing to frequently reuse cached prompts.
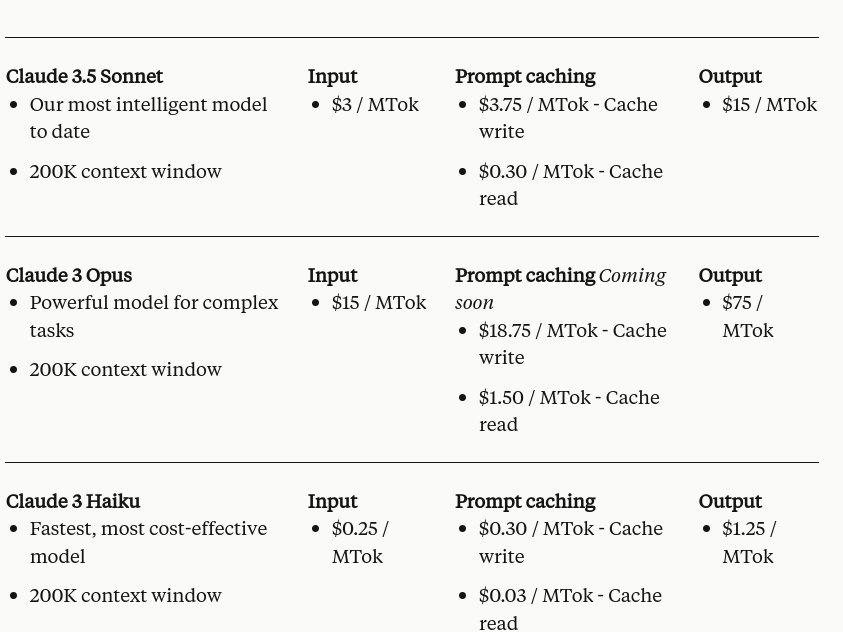
Prompt caching prices. (Source)
Early adopters have reported significant improvements in both speed and cost across various use cases. For example, chatting with a book using a 100,000 token cached prompt saw a 79% reduction in latency and 90% cost reduction.
Interestingly, it seems like prompt caching will become an industry norm at this rate.
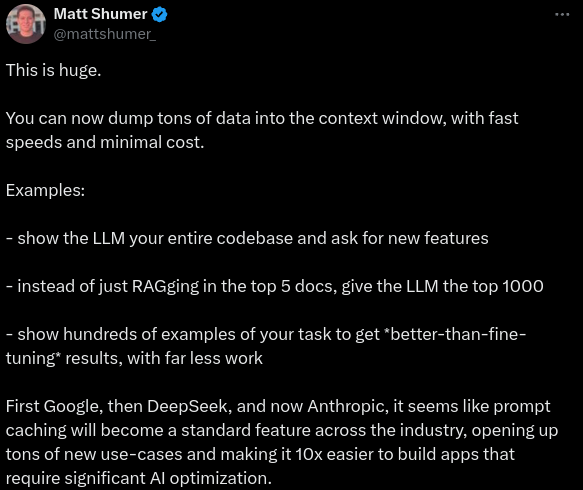
Matt Shumer pointed out that Google, DeepSeek, and Anthropic have all incorporated prompt caching. (Source)
Grok-2, GPT-4o, and Gemini Live Enter the Arena
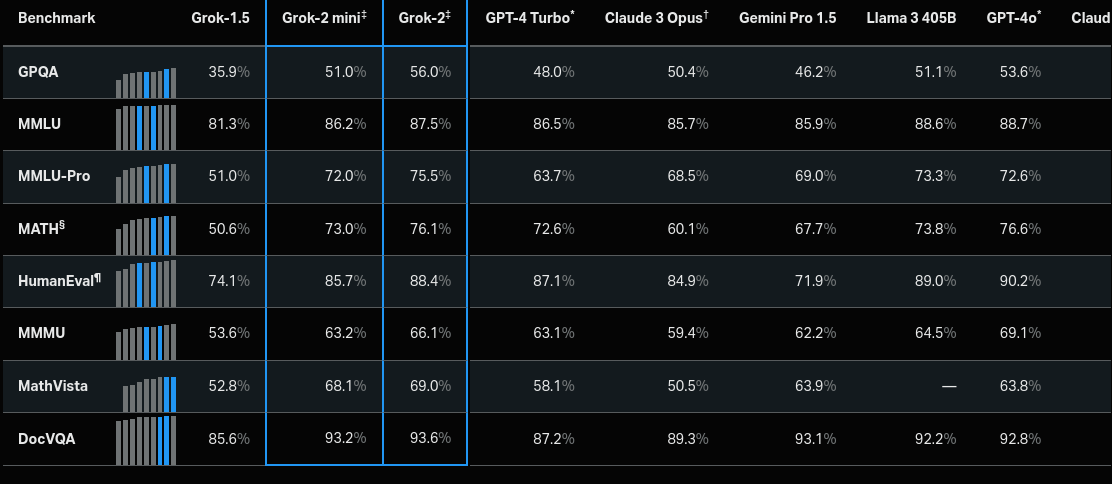
Grok-2 and Grok-2 mini show notable improvement in various benchmarks compared to Grok-1.5 and other SOTA models. (Source)
Grok-2 and its smaller version, Grok-2 mini (another SLM), were released and showed significant improvements in chat, coding, and reasoning over Grok-1.5. Grok-2, tested under the name "sus-column-r," outperforms models like Claude 3.5 Sonnet and GPT-4-Turbo on the LMSYS leaderboard.
Grok-2 shows superior reasoning, factual accuracy, and tool use, particularly excelling in academic benchmarks such as MATH, MMLU, and DocVQA. Grok-2 is integrated into the X app, providing advanced AI assistance, real-time information, and enhanced search functionalities for Premium users.
It was also added to the LM Arena leaderboard, which compares various LLMs. The leaderboard includes a win-rate heatmap, showing how Grok-2 performs against other models in head-to-head comparisons.
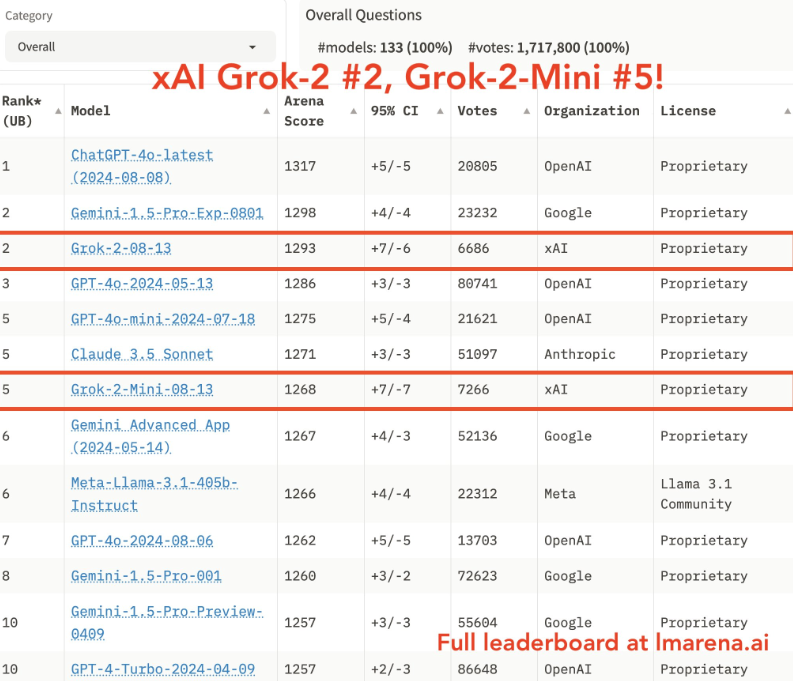
Grok-2 has climbed to the top of the leaderboard. (Source)
Grok-2’s performance is comparable to top LLMs, only losing to the latest GPT-4 model and Gemini-1.5 pro. Pretty impressive considering that xAI was only founded in March 2023 and already caught up to the likes of OpenAI.
Meanwhile, OpenAI launched a new GPT-4o model in ChatGPT, enhancing multi-step reasoning and detailed explanations, leading to more accurate and logical responses. The new model independently generates images, surpassing DALL-E 3 in both speed and visual accuracy, improving the integration within ChatGPT.
Users noticed significant improvements in both reasoning and image generation, leading to better quality outputs and a more seamless experience.
Google didn’t just sit on the sidelines and X.ai and OpenAI released new models. They unveiled Gemini Live, a conversational AI voice assistant, at its Made by Google event alongside new Pixel phones, AI photo editing tools, and Pixel Buds Pro 2 with Gemini AI. The Gemini Live demo had some issues during the presentation.
Q’s Efficiency Gains and Jassy's Long-Term Confidence

Amazon CEO Andy Jassy. (Source)
Amazon remains "very bullish" on AI's medium to long-term impact across all businesses, with their AI business already at a "multibillion dollar revenue run rate".
We’re seeing Amazon leverage AI in its e-commerce business, including an AI shopping assistant called Rufus, apparel simulation features, and a "Project Private Investigator" using AI and computer vision to detect product defects.
On AI costs, Jassy stated Amazon has developed expertise in managing capacity for AWS and AI customers. While investing significantly in AI infrastructure, they still see more demand than current capacity. AWS brought in $26.3 billion in Q2, up 19% year-over-year, with an annualized revenue run rate over $105 billion.
Jassy also mentioned that Amazon’s AI assistant, Amazon Q, has significantly reduced software upgrade times, cutting the average time to upgrade an application to Java 17 from 50 developer days to just a few hours.
This efficiency has saved Amazon an estimated 4,500 developer-years of work, with 79% of AI-generated code reviews being shipped without additional changes. The upgrades have not only saved time but also enhanced security and reduced infrastructure costs, providing an estimated $260 million in annualized efficiency gains.
Amazon Q's success comes after initial challenges, including issues with incorrect outputs or "hallucinations". These were addressed by expanding the team of human reviewers to fine-tune the chatbot's outputs.
AI Chip Race Heats Up as Huawei Challenges Nvidia While Softbank Pivots from Intel

Huawei’s latest AI chip. (Source)
There always seems to be something going on in the AI chip market. Huawei is developing the Ascend 910C AI chip to compete with Nvidia's GPUs in the Chinese market, particularly against the HGX H20 and the rumored Blackwell-based B20.
Major Chinese companies like Baidu and China Mobile have already tested the chip, with results reportedly on par with Nvidia's H100.
Expected demand for the Ascend 910C could exceed 70,000 units, with shipments targeted to start in October, but production isn’t going as smoothly as expected because of U.S. sanctions.
The Ascend 910C aims to improve upon its predecessor, the Ascend 910B, by addressing yield issues and enhancing performance.
Previously, we looked at how Intel’s discussions with OpenAI were a huge turning point in the AI chip market. Intel’s story continues as SoftBank halted its AI chip development partnership with Intel, since Intel had issues meeting production volume and speed requirements. SoftBank is now negotiating with TSMC, the world's largest contract chipmaker, for AI chip production.
SoftBank's Project Izanagi aims to develop AI processors to rival Nvidia’s GPUs, initially relying on Intel’s capacity but now looking to TSMC. SoftBank plans to establish AI data centers globally by 2026 and is developing AI chips with Arm, targeting a prototype by 2025.
AI Image Generation Leaps Forward With Google’s Imagen 3, Runway’s Gen-3, and Midjourney's Unified Editor

Example of an image produced by Imagen 3. (Source)
After releasing the next generation of Gemma 2 models, Google released Imagen 3, an advanced AI text-to-image generator. This version was first announced during Google I/O in May 2024.
Imagen 3 introduces significant improvements in image generation, producing visuals with better detail, richer lighting, and fewer distracting artifacts compared to previous iterations. It aims to enhance realism and reduce errors in the generated images.
Users can interact with the generated images by highlighting specific sections and applying changes based on their descriptions, offering a more refined and customizable image creation experience.
AI image generators continued to see more releases with Runway ML officially launching Gen-3 Alpha Turbo, an upgraded AI video generation model, promising seven times faster performance at half the cost compared to its predecessor, Gen-3 Alpha.
The new model is accessible across all subscription plans, including free trials. It's priced at 5 credits per second of generated video, making it more affordable and widely available.
Gen-3 Alpha Turbo prioritizes speed, significantly reducing video generation time. This improves workflow efficiency, particularly for users needing quick turnarounds.
Early users have praised the model's speed and quality, with some still favoring the original for certain use cases - though the faster version is well-received for simpler tasks.
Midjourney introduced a new web editor that unifies inpainting, outpainting, and other tools into a single interface, making it easier to edit AI-generated images seamlessly. The new editor includes a more precise virtual brush for inpainting, replacing older tools, allowing for finer control over image edits.
Harvey’s Impressive Retention
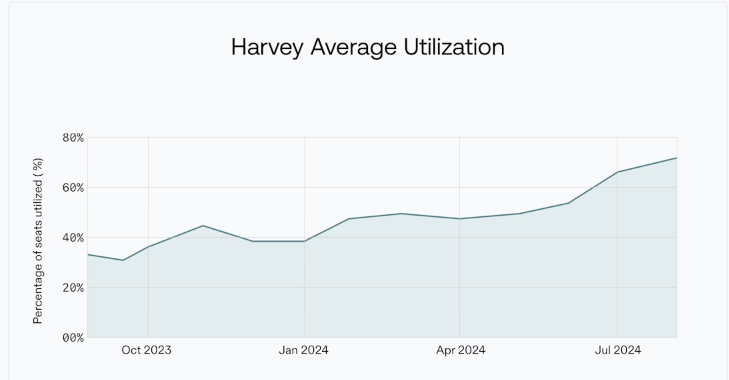
Harvey showed a notable increase in user retention. (Source)
Harvey, an AI platform for professional services, has seen significant growth in utilization, more than double from 33% in August 2023 to 69% in August 2024 across all users.
User retention rates for Harvey have remained consistently high, hovering around or above 70% after one year - exceptional for enterprise SaaS and legal tech.
In particular, three case studies of BigLaw firms show rapid and substantial adoption of Harvey:
Firm #1 reached 93% utilization by month 12
Firm #2 jumped from 19% to 97% utilization in one month
Firm #3 exceeded 100% utilization from month 4 onwards, peaking at 128% by month 10.
Harvey's success in rapid onboarding and consistent usage over time highlights its effectiveness in delivering immediate value, ease of integration into existing systems, and potential to provide firms with competitive advantages in service delivery and client satisfaction.
Not to mention that Harvey recently had a successful funding round involving tech giants like OpenAI and Google. Harvey’s chatbot was able to impress OpenAI executives with an 86% accuracy rate, with the deal making Harvey the highest value startup in OpenAI’s portfolio.
Claude Hits $1M Mobile Milestone
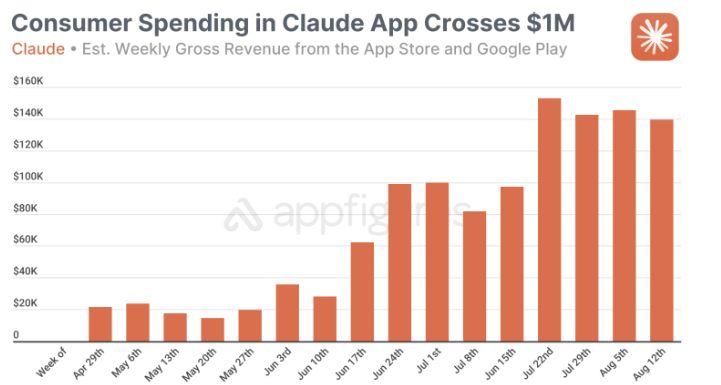
Graph of consumer spending in Claude App in recent weeks. (Source)
Anthropic’s Claude has crossed $1 million in gross mobile app revenue across iOS and Android in 16 weeks since launch. Nearly half (48.4%) of Claude's mobile revenue has been generated by users in the US.
It’s certainly an impressive milestone, but Claude still ranks far behind ChatGPT, which is No. 1 by overall downloads and No. 26 by revenue in the US on iOS. Claude is only 95th in the Productivity category by downloads and 68th by revenue.
Claude reached the $1 million revenue mark faster than competitors like Microsoft's Copilot (19 weeks) and Perplexity (22 weeks), but significantly slower than ChatGPT (3 weeks).
Advancements in AI Research
Google not only showed that 7B models can be run in browsers, but they also published an interesting paper that made notable progress in black-box optimization. Moreover, another paper looking at the impact of code data in LLM pre-training also caught our eye.
We saw notable advancements in automated theorem proving, efficient model upcycling, and novel frameworks for evaluating AI systems.
Google's Vizier Algorithm Outperforms Industry Baselines in Black-Box Optimization
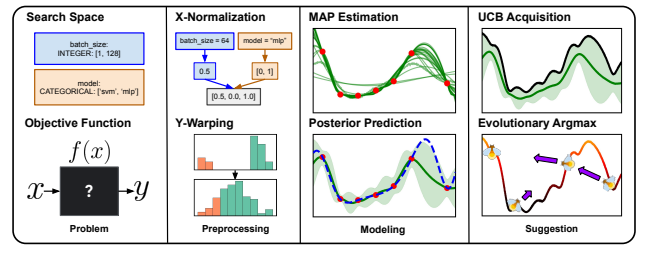
Main components of the algorithm. (Source)
Researchers from Google DeepMind have formalized and open-sourced the algorithm behind Google Vizier, one of the world's largest black-box optimization services.
It looks at the challenge of creating a robust, versatile, and production-grade Bayesian optimization system that can handle a wide range of optimization scenarios, from high-dimensional spaces to categorical parameters and multi-objective optimization.
The algorithm employs a Gaussian process bandit optimization approach with several key innovations, including sophisticated input and output preprocessing, flexible acquisition functions with trust regions, and a customized Firefly algorithm for acquisition optimization.
DeepMinds’s Vizier algorithm consistently outperforms other industry-wide baselines across multiple axes, including non-continuous parameters, high-dimensional spaces, batched settings, and multi-metric objectives. For example, it demonstrates up to 8.2% relative improvement in natural language reasoning tasks compared to text-only pre-training.
Code in LLM Pre-training Improves Natural Language Reasoning by 8.2%
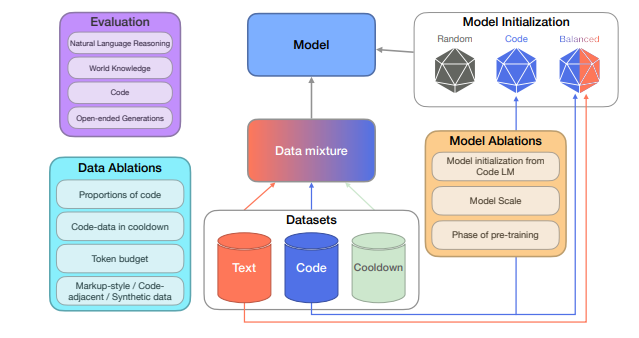
Framework overview. (Source)
Cohere researchers conducted a comprehensive study to understand the impact of code data in pre-training LLMs on a variety of downstream tasks beyond code generation.
The team employed a systematic approach, conducting extensive ablations across various dimensions:
Model initialization strategies
Different proportions of code data
Quality and properties of code data
Role of code in pre-training cooldown
Their experiments spanned models ranging from 470 million to 2.8 billion parameters, evaluating performance on natural language reasoning, world knowledge, code generation, and open-ended text generation tasks.
Key findings include:
Compared to text-only pre-training, the best variant with code data showed relative increases of 8.2% in natural language reasoning, 4.2% in world knowledge, and a 6.6% improvement in generative win-rates
Code performance saw a dramatic 12x boost
Including code during the cooldown phase led to further improvements across all tasks
High-quality synthetic code data, even in small proportions, had a strong positive impact on both code and non-code task performance
Results make it clear that code is a critical building block for generalization far beyond coding tasks. Investments in code quality and preserving code during pre-training can have positive impacts across a wide range of AI capabilities.
Automating the Full Cycle of ML Research With The AI Scientist
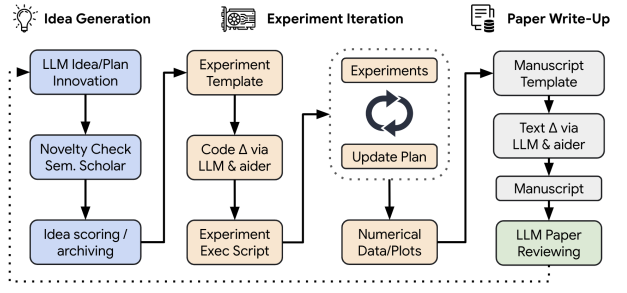
The AI Scientist overview. (Source)
Sakana AI developed The AI Scientist, which aims to automate the entire scientific discovery process in ML, from idea generation to paper writing and peer review. It addresses the challenge of scaling up scientific research and democratizing access to cutting-edge AI developments by leveraging LLM to perform tasks traditionally done by human researchers.
The AI Scientist uses a combination of LLM-based agents for idea generation, experiment design and execution, paper writing, and peer review. It employs techniques such as chain-of-thought reasoning, self-reflection, and automated code generation to carry out complex research tasks. The system was tested on three ML subfields: diffusion modeling, transformer-based language modeling, and learning dynamics.
Results show that The AI Scientist can generate hundreds of research papers at a surprisingly low cost (approximately $15 per paper), with some papers achieving scores that exceed the acceptance threshold for top ML conferences according to an automated reviewer. The framework demonstrates the potential for AI to significantly accelerate scientific progress and lower barriers to entry in AI research.
Boosting LLM Decision-Making in Interactive Environments Using AgentQ

Example of an input and output to the Agent. (Source)
MultiOn and Stanford University researchers introduced Agent Q - a framework that aims to improve the reasoning and decision-making capabilities of LLM in interactive, multi-step environments like web navigation.
It tackles the issue of generalizing LLMs to agentic tasks, where they need to understand how their actions affect the environment and make complex decisions over multiple steps.
Agent Q combines guided Monte Carlo Tree Search (MCTS) with a self-critique mechanism and iterative fine-tuning using an off-policy variant of Direct Preference Optimization (DPO). The framework uses AI feedback and self-criticism to guide search steps, and learns from both successful and unsuccessful trajectories through offline reinforcement learning.
Drastic improvements were seen on the WebShop benchmark and real-world booking scenarios. For example, it boosts a Llama-3 70B model's zero-shot performance from 18.6% to 81.7% success rate on a real-world reservations booking website after a single day of data collection, and further to 95.4%.
It’s worth noting that the approach used by Agent Q was also used by Salesforce to achieve 55% on SWE-Bench Lite - a benchmark used to test how well the AI model can solve Github issues, with the Lite version being a slightly easier benchmark than the original SWE-Bench.

Salesforce also used a similar approach. (Source)
DeepSeek Advances Automated Math Reasoning
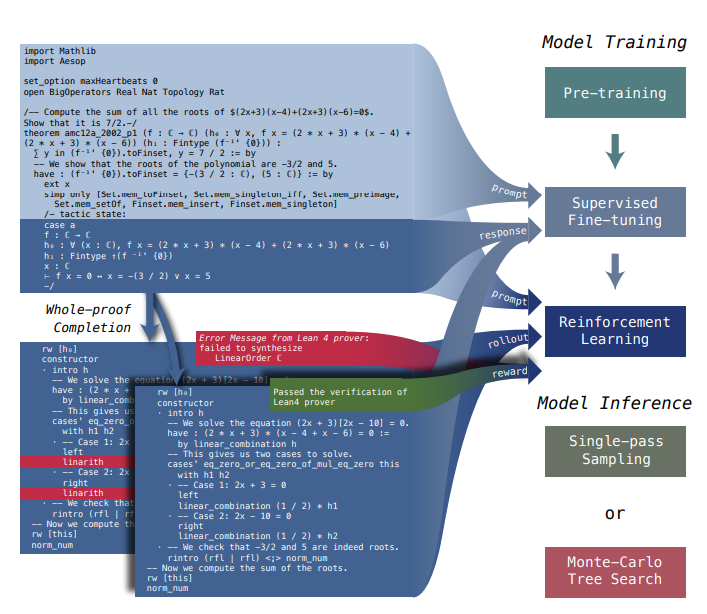
DeepSeek-Prover-V1.5 framework overview. (Source)
DeepSeek-Prover-V1.5 is an open-source language model designed for theorem proving in Lean 4, since automating complex mathematical reasoning is a tricky area for language models to handle. This model is a step up from its predecessor by optimizing both training and inference processes, aiming to improve performance on formal theorem proving tasks.
Some of the key components include:
Large-scale mathematical pre-training
Formal mathematics corpus construction and augmentation
Online reinforcement learning from proof assistant feedback
Novel Monte-Carlo tree search methodology for long-term planning in theorem proving
DeepSeek-Prover-V1.5 uses a combination of supervised fine-tuning, reinforcement learning, and a new variant of Monte-Carlo tree search called RMaxTS, which employs an intrinsic-reward-driven exploration strategy to generate diverse proof paths.
Results show significant improvements over DeepSeek-Prover-V1, achieving SOTA results on the test set of the high school level miniF2F benchmark (63.5%) and the undergraduate level ProofNet benchmark (25.3%).
Efficient Upcycling of Dense Models Into MoE With BAM
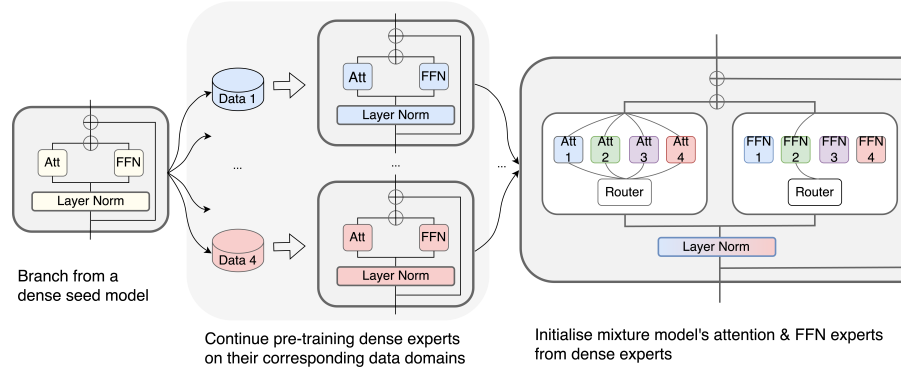
The three phases of BAM. (Source)
BAM (Branch-Attend-Mix) is a new approach to efficiently upcycle pre-trained dense models into Mixture of Experts (MoE) models. Initializing MoEs is tough since they’re computationally expensive to train from scratch, so BAM makes full use of specialized dense models' parameters to tackle this problem.
BAM operates in three phases:
Branching (creating copies of a pre-trained seed model)
Continued pre-training (specializing each copy on different domains)
Mixture model training (initializing MoE layers using the specialized models
It introduces a soft-variant of Mixture of Attention (MoA) layers and employs a parallel attention transformer architecture to improve efficiency.
BAM consistently outperforms baseline methods in both perplexity and downstream task performance across various domains, with experiments conducted on seed models ranging from 590 million to 2 billion parameters. It’s a big step forward in MoE initialization, so we might see more efficient training of large-scale language models with superior performance in the future.
Frameworks We Love
Some frameworks that caught our attention include:
DreamCinema: Simplifies film creation by using generative AI to automate the production of 3D characters and cinematic elements
RuleAlign: Enhances LLMs like GPT-4 for medical diagnostics by aligning them with specific diagnostic rules
PCGRL+: Designed to train AI agents to generate game levels based on specific quality metrics.
SigLLM: Uses large language models for time series anomaly detection by converting time series data to text
MVInpainter: Reformulates 3D editing as a multi-view 2D inpainting task, enabling novel view synthesis and editing for in-the-wild scenes without relying on explicit camera poses.
RAGchecker: comprehensive evaluation framework for Retrieval-Augmented Generation (RAG) systems that incorporates diagnostic metrics for both retrieval and generation modules.
If you want your framework to be featured here, reply to this email and say hi :)
Conversations We Loved
Wolfram’s highly detailed discussion about his perspective on ML took the spotlight. Although there was a big focus on the theoretical aspects, it’s still useful to consider as it can provide a different perspective for practical applications of ML.
While the strange Strawberry account was gaining all that attention, there was a pretty notable advancement that slipped under the radar with rStar. Moreover, Y Combinator CEO let us AI startups in on a little secret on how they can quickly build trust with customers using golden magic demos.
From Randomness to Intelligence: Wolfram's New Perspective on ML

Wolfram’s discussion about machine learning. (Source)
A recent blog post by Stephen Wolfram caught our attention this week, offering intriguing insights into the fundamental workings of machine learning systems. Wolfram explores minimal models that capture the essence of machine learning, stripping away complexities to reveal core principles.
Wolfram introduces simple, visualizable models like "rule arrays" that can perform machine learning tasks. These models suggest that machine learning works by "sampling" from the computational universe rather than building structured mechanisms.
He also argues that the power of machine learning comes from leveraging computational irreducibility as a "natural resource." Moreover, Wolfram mentions that we’re at a point where we can achieve notable results with machine learning techniques like neural networks, but we don’t truly understand how we’re able to get such results.
The Overlooked AI Reasoning Breakthrough Amid Strawberry Hype

Tekparmak brought light to an overlooked advancement. (Source)
A thread by Tekparmak caught our attention amidst all the Strawberry hype discussing a new approach called rStar. This method uses a generator LLM to create solution trajectories and a discriminator LLM for "peer review," reminiscent of the GAN architecture.
rStar has demonstrated superior performance among multi-round self-improving approaches for AI reasoning tasks. This means that compared to other methods that use multiple iterations or rounds to improve their performance, rStar is currently achieving the best results.
Interestingly, base model generators perform well with instruct discriminators, and the gap between GPT-4 and smaller open-weight models like Phi-3 mini is not as significant as one might expect.
While breakthroughs like OpenAI's Project Strawberry generate buzz, there's still ample room for innovative approaches using existing models and techniques.
How AI Startups Can Win With Powerful Demos

Tan’s discussion about the power of a golden magic demo. (Source)
Y Combinator CEO Garry Tan raised an interesting point about just how important a golden magic demo is for AI startups. But why is that?
He mentions that a golden magic demo shows the benefit and value of the product right away, indicating how they could accomplish days worth of work in just 10 minutes. Repetitive tasks are a massive pain point customers face, so showing how AI can automate these tasks and boost productivity is a great way for startups to immediately show their solution can solve an important problem.
Casetext was used to highlight this point, with the example of AI being able to quickly detect nuances in emails for lawyers to use as evidence for potential fraud. Their golden magic demo showed how lawyers could save a ton of time with AI, so they could quickly see the power of Casetext’s solution by the end of the demo.
Tan also mentioned that a successful golden magic demo is something that Y Combinator sees in a lot of successful LLM-based startups, which makes it pretty encouraging for other startups to do the same.
Money Moving in AI
We saw the success of three funding rounds for Story, Cursor, and Defcon - all of which were under $100 million. Interestingly, each company focuses on pretty different applications in AI: Story in blockchain, Cursor in coding, and Defcon in military logistics.
Okpey and Elise AI also had successful funding rounds, with Opkey raising $47 billion and Elise AI raising $75 million. On the other hand, AMD decided to challenge Nvidia’s chip dominance by acquiring ZT systems for $5 billion.
AMD Acquires ZT Systems for $5 Billion to Challenge Nvidia
AMD has made a bold move in the AI chip market by agreeing to acquire ZT Systems, a New Jersey-based server maker, for nearly $5 billion in cash and stock. This acquisition, which combines AMD's silicon and software capabilities with ZT's systems expertise, aims to accelerate the deployment of AMD-optimized data center AI solutions at scale for cloud and enterprise customers.
Story Raises $80 Million in Series B Funding Round
Story, a startup building a blockchain-based platform for IP tracking and monetization in the age of AI, has secured $80 million in Series B funding led by Andreessen Horowitz's crypto division, with participation from Polychain Capital and other notable investors. The round values Story at $2.25 billion post-money and brings its total funding to $143 million.
Elise AI Raises $75 Million in Series D Funding
EliseAI, a startup developing AI-powered property management tools, has secured a $75 million Series D funding round, valuing the company at $1 billion. Led by Sapphire Ventures with participation from Point72 Private Investments, Divco West, Navitas Capital, and Koch Real Estate Investments, this investment brings EliseAI's total funding to $140 million.
Cursor Secures $60 Million in Series A Funding
Cursor, an AI-powered coding tool startup, has raised $60 million in Series A funding from prominent investors including Andreessen Horowitz, Thrive Capital, OpenAI, and notable tech founders. The company, which aims to create a "magical tool" for writing the world's software, has grown to over 30,000 customers across major enterprises, research labs, and startups.
Cursor has even started to go viral on X off a video showing how an 8 year old can use it to start coding.
Cursor is making coding more accessible. (Source
Opkey Raises $47 Million in Series B Funding
Opkey, an AI-powered continuous test automation platform for enterprise systems, has secured $47 million in Series B funding led by PeakSpan Capital, with participation from existing investors. The funding will fuel Opkey's mission to accelerate product development and expand its global market presence.