- GenAI360 - Weekly AI News
- Posts
- OpenAI DevDay 2024, Nvidia Unveils NVLM 1.0, Meta Advances Video Generation
OpenAI DevDay 2024, Nvidia Unveils NVLM 1.0, Meta Advances Video Generation
Plus, Last Remaining FREE Tickets to RetrieveX on Oct 17 for Our Subscribers
GenAI360 Exclusive: Last Week to Get Free Tickets for RetrieveX Conference on Oct 17 in San Francisco.
Come hear from the creators of PyTorch, Albumentations, Meta Chameleon, Kubeflow, CAFFE, along with leaders from Microsoft, AWS, Bayer, Flagship Pioneering, Cresta, VoyageAI, Omneky how to build best retrieval for AI.
If you're executive who's considering or working on GenAI projects, fill in the form below for a complimentary ticket for the conference - hurry up because tickets are limited! Please note that the conference is in-person only.
Date: October 17, 10:30am - 7pm PT
Venue: The Midway, 900 Marin St, San Francisco
Key Takeaways
John Hopfield and Geoffrey Hinton, the Godfather of AI, win Nobel Prize… in Physics.
OpenAI announced new API features, including a Realtime API for voice-to-voice conversations and Vision fine-tuning for improved image tasks like object detection.
Nvidia released NVLM-D-72B, a large multimodal model rivaling GPT-4o and Claude, with its model weights publicly available.
Liquid AI released Liquid Foundation Models (LFMs), delivering SOTA performance with a smaller memory footprint.
Meta's Movie Gen lets users create videos and edit personal images using simple text inputs, producing HD media.
FlashMask optimizes attention mechanisms by introducing a column-wise sparse representation for attention masks, improving memory efficiency for LLMs handling sequences up to 128K tokens.
PlasmidGPT is a transformer-based model for designing plasmid DNA which improves annotation accuracy by 81%.
Got forwarded this newsletter? Subscribe below👇
The Latest AI News
Folks, busy week as always. OpenAI took the spotlight in terms of AI news last week yet again. It wasn’t all positive though, as there was yet another OpenAI exodus with four key members leaving (and two of them joining competitor companies already). Although there were some neat announcements for new API features at OpenAI DevDay.
Meanwhile, we saw new model releases from the likes of Nvidia, Liquid AI, and Resolve AI, as well as developments in video generation AI.
OpenAI Unveils Realtime API, Vision Fine-Tuning, and More at DevDay 2024
OpenAI Devday 2024 took place last week and there were some huge feature announcements. Are they worth a loss of $44B from 2023 to 2028? We'll see.
Here’s a quick rundown of what OpenAI revealed in terms of API features:
Realtime API: For devs looking to quickly add speech-to-speech into apps, they’ll be glad to hear about this. Voice assistant development is a whole lot easier since Realtime API combines transcription, text reasoning, and text-to-speech into a single API call. Currently available to paid developers with text and audio input/output tokens priced at $0.06/minute for input and $0.24/minute for output.
Vision: Further multimodal developments were seen in the vision update, which means that GPT-4o now supports fine-tuning with images. The plans are for free vision fine-tuning tokens to be available until October 31 2024, after which training and inference will be priced based on token usage.
Prompt caching: Devs can now reduce costs and latency by reusing previously seen input tokens through the new Prompt Caching feature in the GPT-4o models, offering discounts and faster processing. Prompt Caching automatically applies on prompts over 1,024 tokens, and cached prompts receive a 50% discount on input tokens.
Model distillation: This feature helps improve performance at lower costs as it allows for outputs from larger models like GPT-4o to be used to fine-tune smaller, cost-efficient models such as GPT-4o mini. Model Distillation is available for all devs with free training tokens until October 31 2024, and standard pricing thereafter.
Canvas: A new interface for writing and coding projects with ChatGPT, allowing collaboration beyond basic conversation. It enables direct editing and feedback - similar to a code reviewer or copy editor. It's currently in early beta with plans for rapid development based on user feedback.
AI Video Generation Heats Up: Movie Gen, VidGen-2, and OpenFLUX Make Waves
A bunch of model releases were seen in the AI video generation space last week.

Example of a video produced by Meta’s Movie Gen. (Source)
Meta introduced Movie Gen, a breakthrough generative AI research project for media.
It encompasses multiple modalities including image, video, and audio generation and editing.
The system allows users to produce custom videos and sounds, edit existing videos, and transform personal images into unique videos using simple text inputs. Movie Gen uses a 30B parameter transformer model for video generation.
A quick overview of Movie Gen’s main features:
Video Generation: Using a 30B parameter transformer model, Movie Gen can create high-quality, high-definition videos up to 16 seconds long at 16 fps from text prompts.
Precise Video editing: Movie Gen's editing capabilities allow for both localized and global changes to existing videos. Users can add, remove, or replace elements, or modify entire backgrounds and styles using text prompts. Unlike traditional editing tools, Movie Gen preserves original content while targeting only relevant pixels.
Audio Generation: A 13B parameter audio model can generate high-fidelity audio up to 45 seconds long, including ambient sound, sound effects, and background music, all synchronized with video content.
Meanwhile, HelmAI’s VidGen-2 offers 2X higher resolution than its predecessor, generating video sequences at 696 x 696 resolution. It improves realism at 30 fps, with frame rates ranging from 5 to 30 fps. It can generate videos without an input prompt or with a single image or input video as the prompt.
The model generates driving scene videos across multiple geographies, camera types, and vehicle perspectives. It produces highly realistic appearances and temporally consistent object motion. VidGen-2 learns and reproduces human-like driving behaviors, simulating the motions of the ego-vehicle and surrounding agents in accordance with traffic rules.
Note that VidGen-2 was trained on thousands of hours of diverse driving footage using NVIDIA H100 Tensor Core GPUs.
Midjourney’s competitor FLUX by Black Forest Labs also saw a new release called OpenFLUX.1, which is a fine-tuned version of the FLUX.1-schnell model. The main aim of this model was to train out the distillation to leave behind an open-source model that can be fine-tuned.
Nvidia Unveils NVLM 1.0 and Powers Brave's Local LLMs
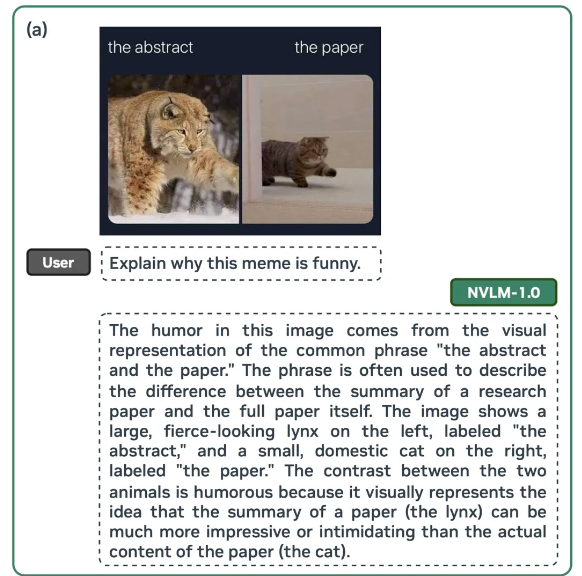
Nvidia’s new model can respond to prompts containing text and images. (Source)
Even though we know Nvidia mainly for providing AI chips, they unexpectedly announced NVLM 1.0 - a family of large multimodal language models.
The flagship model, NVLM-D-72B, with 72 billion parameters, is reported to perform on par with or better than leading proprietary models like GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro in various tasks. Unlike its competitors, Nvidia is making NVLM 1.0's model weights and training code publicly available.
NVLM 1.0 demonstrates strong performance in vision-language tasks, effectively processing and reasoning about both text and images. The model shows versatility in tasks requiring OCR, reasoning, localization, common sense, world knowledge, and coding abilities.
Additionally, after multimodal training, NVLM-D-72B shows improved accuracy on text-only tasks compared to its LLM backbone, indicating enhanced overall language understanding.
Brave, a privacy-focused web browser, has launched Leo AI, a smart AI assistant. Leo AI enhances user experience by summarizing articles and videos, surfacing insights from documents, and answering questions.
Ollama is an open-source project that sits on top of llama.cpp and simplifies AI model integration for applications. It handles tasks like downloading and configuring specific AI models, making it easier for applications to access local AI capabilities. NVIDIA optimizes tools like Ollama for their hardware to deliver faster, more responsive AI experiences on RTX GPUs.
OpenAI Exodus: Episode… (which one are we one now?)
This isn’t the first time we’ve seen various key members leave OpenAI in such a short span of time.
Durk Kingma isn’t as well-known as some of the other figures, but he's a co-founder of OpenAI who announced his move to Anthropic.
Kingma's hiring is part of a broader pattern of high-profile recruitments by Anthropic. The company has recently brought on board other notable figures from OpenAI, including Jan Leike (OpenAI's former safety lead) and John Schulman (another OpenAI co-founder).
Barret Zoph also decided to leave OpenAI, who was around for the entire ChatGPT boom in 2022 since was a part of the post-training team. Those weren’t the only departures, as Mira Murati left OpenAI after 6 and a half years. Altman made a statement about Mira leaving, talking about how taxing it is to be a leader at the company.
Lastly, Sora co-lead Tim Brooks released a short statement mentioning how he’ll be joining DeepMind to work on video generators and world simulators after spending 2 years at OpenAI working on Sora.
Resolve AI Launches Efficient AI Model for DevOps Operations
Resolve AI introduced the world's first AI production engineer, designed to autonomously troubleshoot and resolve production issues. The company aims to empower engineers to focus on innovation rather than routine maintenance tasks.
The goal is to significantly reduce mean time to resolution (MTTR) and accelerate engineering teams' productivity.
The company built an agentic platform that integrates with tools like AWS, Kubernetes, observability stacks, GitHub, and Slack. It constructs a comprehensive knowledge graph of a company's production environment.
The AI agent leverages this knowledge graph to troubleshoot incidents, analyze source code changes, detect anomalies, query logs, and suggest remediation actions. Resolve acts as an always-on partner, handling operational tasks like answering natural language queries and translating them into observability actions.
Advancements in AI Research
Last time, we saw a completely unexpected release in terms of biotech AI with Google’s whale bioacoustics model. We’re seeing more biotech developments with PlasmidGPT, which is used to annotate plasmid DNA sequences (as the name suggests).
Other developments include a new framework for multi-agent exploration and a new extension to the FlashAttention algorithm, as well as new generative AI models that take efficiency to another level.
Liquid Foundation Models: A New Approach to Efficient and Powerful AI
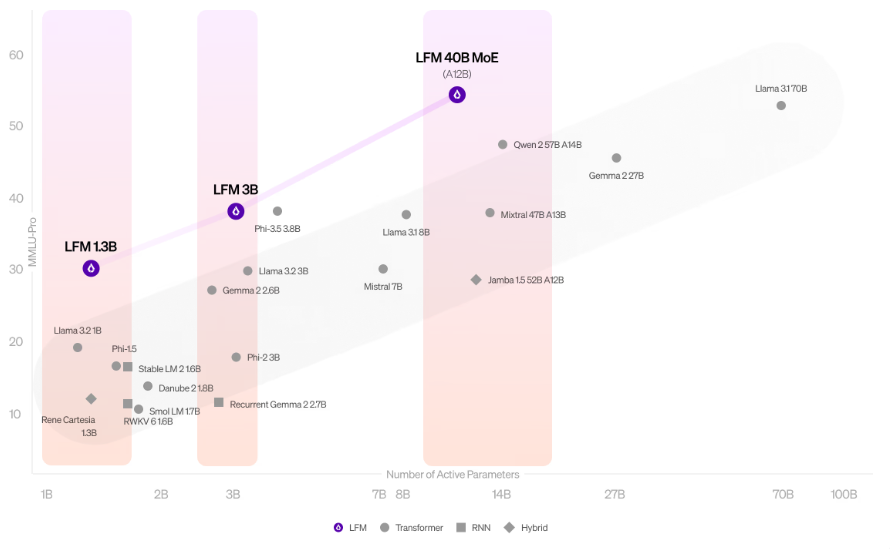
LFMs performance/size trade-offs are better than other models. (Source)
Researchers from Liquid AI have introduced Liquid Foundation Models (LFMs), a new generation of generative AI models that aim to achieve SOTA performance while maintaining a smaller memory footprint and more efficient inference.
LFMs address several challenges in current AI model development, including the trade-off between model size and performance, memory efficiency, and the ability to handle long-context tasks. The researchers proposed a new architecture that diverges from the traditional transformer-based models.
Impressive results were reported across the board:
LFM-1B achieves the highest scores across various benchmarks in the 1B parameter category.
LFM-3B outperforms previous generation 7B and 13B models on multiple benchmarks.
LFM-40B offers performance comparable to larger models while using only 12B activated parameters.
They also show strong performance in multilingual capabilities and can effectively utilize their full 32k token context length. This efficiency enables long-context tasks on edge devices for the first time, so we might see new applications in areas like document analysis, context-aware chatbots, and improved RAG performance.
PlasmidGPT: AI-Powered Plasmid Design and Annotation
PlasmidGPT is a generative framework for designing and annotating plasmid DNA sequences. It addresses the challenges in automating plasmid design and leveraging the growing collection of engineered plasmid sequences.
Some of the main innovations include:
A decoder-only transformer model pretrained on 153,000 engineered plasmid sequences from Addgene.
The ability to generate de novo plasmid sequences that share characteristics with engineered plasmids but have low sequence identity to the training data.
Conditional generation capabilities, allowing users to specify starting sequences or fine-tune the model for specific vector types.
Effective prediction of various sequence-related attributes for both engineered and natural plasmids.
They showed that PlasmidGPT can generate plasmids with genetic part distributions similar to those in the training sequences. The model also outperforms previous approaches in predicting attributes like lab of origin, with a top-1 accuracy of 81% and top-10 accuracy of 92%.
Optimizing Attention for Long-Context LLMs with FlashMask
FlashMask is an extension to the FlashAttention algorithm that significantly improves the efficiency and flexibility of attention mechanisms in LLMs.
It addresses the growing challenge of handling complex masking requirements in various LLM training and inference scenarios. FlashMask introduces a column-wise sparse representation of attention masks, allowing for efficient handling of a wide range of mask types without compromising computational accuracy.
They introduced optimized kernel implementations that leverage sparsity in the attention mask to skip unnecessary computations. Moreover, extensive evaluation across different attention mask types and models were seen, showing significant throughput improvements in fine-tuning and alignment training of LLMs.
They reported end-to-end speedups ranging from 1.65x to 3.22x compared to existing FlashAttention dense methods. Additionally, FlashMask outperforms the latest counterpart, FlexAttention, by 12.1% to 60.7% in terms of kernel TFLOPs/s.
LLM-Guided Efficient Multi-Agent Exploration Using LEMAE
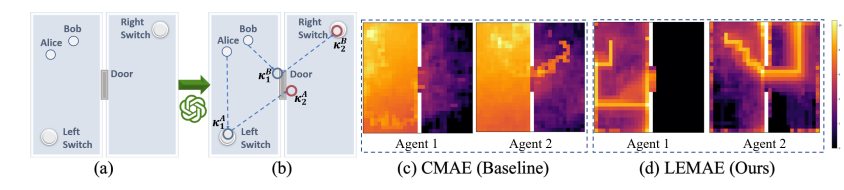
Map of the task “Pass.” (Source)
LLM for Efficient Multi-Agent Exploration (LEMAE) leverages LLMs to enable efficient multi-agent exploration in reinforcement learning. This work addresses the longstanding challenge of efficient exploration in complex multi-agent environments with expansive state-action spaces.
They used LLMs to ground linguistic knowledge into symbolic key states that are critical for task fulfillment. Additionally, a Subspace-based Hindsight Intrinsic Reward (SHIR) mechanism to guide agents toward key states by increasing reward density and a Key State Memory Tree (KSMT) to track transitions between key states and organize exploration were used.
They showed LEMAE significantly outperforms existing SOTA approaches on challenging benchmarks like StarCraft Multi-Agent Challenge (SMAC) and Multiple-Particle Environment (MPE). In certain scenarios, LEMAE achieves a 10x acceleration in exploration efficiency.
Conversations We Loved
A discussion about a new approach to information retrieval from complex documents took the spotlight, since it has benefits like having a much faster indexing process than traditional methods and it’s a lot more accurate when it comes to documents with a lot of visuals in them.
The other discussion that caught our attention was about a new paper by Meta finally giving us some insight into the post-training process of the Llama models.
How Meta's Mixture of Judges Perfects LLM Post-Training
Carr brought up Meta’s new paper. (Source)
If you’ve been wondering about how Meta has been going about the post-training process for the Llama models, you’re in luck as they recently released a paper on "Constrained Generative Policy Optimization" for post-training LLMs.
In particular, Carr put the spotlight on Meta's innovative approach to addressing the challenges of aligning LLMs on multiple tasks simultaneously. The introduction of Mixture of Judge models to achieve a balanced blend of RLHF improvements stood out in particular.
This approach tackles common issues in multi-task alignment like reward hacking, multi-objective conflicts, and contradictory goals. The judges include specialized models for false refusal, precise instruction following, regex math/code reasoning, factuality, and safety.
It emphasized the simplicity and effectiveness of this method, which improves performance across various benchmarks including MATH, Human Eval, ARC, and AlpacaEval.
The Promise of ColPali in Information Retrieval

Leonie’s post introducing ColPali. (Source)
An interesting thread discussing ColPali popped up last week. ColPali is a new approach to information retrieval from complex document types like PDFs.
What caught our eye was the explanation of how ColPali combines two key technologies: the contextualized late interaction mechanism from ColBERT and the Vision Language Model capabilities of PaliGemma.
This innovative approach replaces the traditional multi-step PDF parsing process with a simpler method using "screenshots" of PDF pages, which could change how we handle complex documents in information retrieval tasks. And on that note…
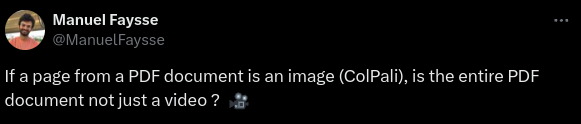
An interesting perspective on ColPali. (Source)
Frameworks We Love
Some frameworks that caught our attention in the last week include:
FakeShield: Multimodal framework designed to address challenges in image forgery detection and localization (IFDL)
MA-RLHF: Incorporates macro actions (sequences of tokens or higher-level language constructs) into the learning process for large language models.
ControlAR: Integrates spatial controls into autoregressive image generation models
If you want your framework to be featured here, reply to this email saying hi :)
Money Moving in AI
There were successful funding rounds for companies developing varied AI applications, including ones we don’t hear about often like liquid cooling solutions for data centers. Poolside, Submer, and Numa all saw successful funding rounds, with Poolside being the biggest winner last week.
Poolside Secures $500 Million
Poolside, a startup developing AI-powered coding software, has secured a massive $500 million investment led by Bain Capital Ventures, valuing the company at $3 billion. This significant funding round, which includes participation from DST Global, StepStone Group, Citi Ventures, and HSBC Ventures.
Submer Raises $55.5 Million in Series C Funding Round
Submer, a Barcelona-based startup specializing in liquid cooling solutions for data centers, has raised $55.5 million in a Series C round at a $500 million valuation. The company's technology, which involves submerging entire server racks in biodegradable, non-conducting coolant. This helps address the growing challenge of heat management in AI-driven data centers.
Numa Secures $32 Million in Series B Funding Round
Numa, an AI startup specializing in customer service automation for auto dealerships, has secured a $32 million Series B funding round, bringing its total raised to $48 million. The company, which pivoted from a general conversational AI product to focus specifically on the automotive industry, claims to be nearing cash-flow break-even with 600 customers across the U.S. and Canada.
Cerebras Files for IPO
Cerebras Systems filed for an initial public offering on September 30, 2024. The company plans to trade on the Nasdaq under the ticker symbol "CBRS". Cerebras positions itself as a competitor to Nvidia in the AI chip market, claiming its WSE-3 chip has more cores and memory than Nvidia's popular H100.
For the first six months of 2024, Cerebras reported a net loss of $66.6 million on $136.4 million in sales. This shows significant growth compared to the same period in 2023, where they had a net loss of $77.8 million on $8.7 million in sales. For the full year 2023, the company reported a net loss of $127.2 million on revenue of $78.7 million.