- GenAI360 - Weekly AI News
- Posts
- September Roundup: 🦙3.2, GPT Next’s 100x Power, $125B Supercomputers
September Roundup: 🦙3.2, GPT Next’s 100x Power, $125B Supercomputers
Plus, free tickets for data leaders for RetrieveX Conference in SF on Oct 17
GenAI360 Exclusive: Unlock Free Tickets for RetrieveX Conference on Oct 17 in San Francisco.
Come hear from the creators of Meta Chameleon, PyTorch, Kubeflow, CAFFE, along with leaders from Microsoft, AWS, Bayer, Flagship Pioneering, Cresta, VoyageAI, Omneky how to build best RAG and LLM-powered workflows.
If you're an engineering leader who's considering or working on GenAI projects, fill in the form below for a complimentary ticket for the conference - hurry up, tickets are limited!
Date: October 17, 10:30am - 7pm PT
Venue: The Midway, 900 Marin St, San Francisco
Key takeaways
Meta introduced Llama 3.2 with vision-capable LLMs (11B and 90B) for document understanding, and lightweight text models (1B, 3B) optimized for mobile devices, supporting on-device processing with improved privacy.
OpenAI Japan announced "GPT Next," projected to be 100x more powerful than GPT-4, with a planned release in 2024.
DeepMind introduced AlphaProteo, an AI system for designing novel protein binders with 3-300x better binding affinities than existing methods.
Google’s NotebookLM is a personalized AI research assistant that helps you chat across all your docs, and even generate audio overviews from uploaded content, creating podcasts and summaries with conversational AI voices.
NVIDIA researchers introduced OP-RAG, outperforming long-context LLMs on the ∞Bench dataset using just 16K retrieved tokens.
The Latest AI News
Just when you thought OpenAI had enough on their plate with Project Strawberry, they dropped some major news in Japan that they’re planning to release another model called GPT Next later in the year. Other major releases included Meta’s Llama 3.2 and Google’s NotebookLM.
There were a bunch of new releases last week too, including LLMs, AI agents, and VLMs. Progress in biotech was also made by DeepMind’s latest model called AlphaProteo.
Meta’s Llama 3.2 and AI Updates
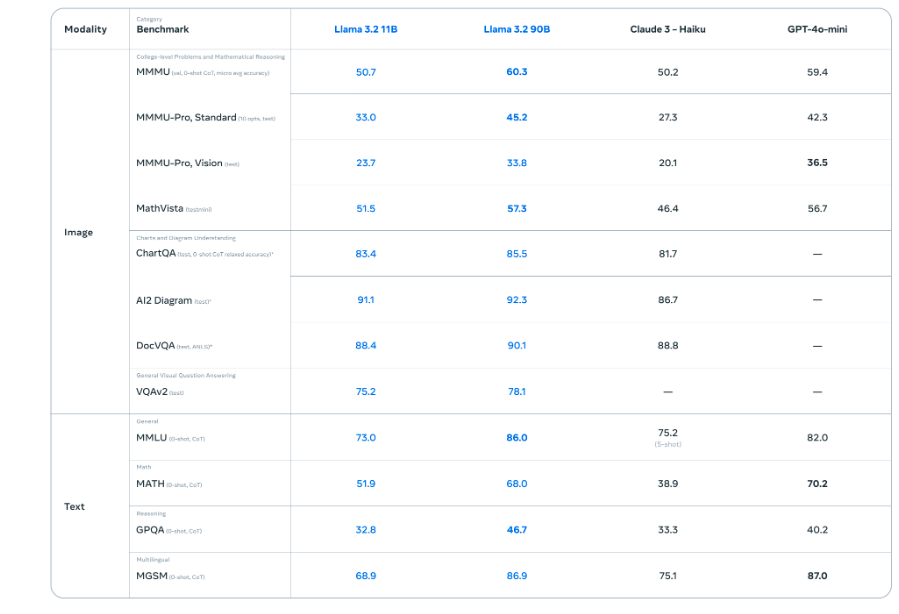
Llama 3.2 performs well on instruction-tuned benchmarks. (Source)
Llama 3.1 recently reached 350+ million lifetime downloads. With this great achievement, Meta shipped another exciting update. Meta's Llama 3.2 includes vision-capable LLMs (11B and 90B) for tasks like document understanding and visual reasoning, as well as lightweight text-only models (1B and 3B) optimized for edge and mobile devices with 128K token support.
Llama 3.2's smaller models are optimized for devices using Qualcomm and MediaTek hardware. As a result, we’ll see faster, private processing for summarization and instruction-following without needing cloud access.
The 11B and 90B models introduce a new architecture integrating pre-trained image encoders with cross-attention layers for high-performance image-text reasoning, making them drop-in replacements for text models.
An important update was also the Llama Stack, a set of APIs for Agents, data generation, inference, guardrails, evals, and more. Aside from that, we saw some updates for Meta’s AI products, with new voice, text generation, and photo understanding capabilities within Messenger, Instagram, and Meta for Business.
Gemini's Upgrade, NotebookLM as an AI Research Assistant, and Arcade's Product Platform
Google announced new versions of Gemini called Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002 models. Standout benefits include 50% price drop, 2x faster outputs, and 3x lower latency.
These models show a 20% improvement in math-related tasks and substantial gains in visual understanding and code generation, so they’re ideal for tasks like summarizing large documents and understanding long videos.
Moreover, Google reduced the output length by 5-20%, speeding up responses without compromising quality, with options for more verbose outputs via prompting strategies. Google also simplified access to the models through AI Studio and Vertex AI, increasing rate limits and improving scalability for developers.
Google also released NotebookLM (only available for English speakers), which lets users upload content, ask questions, and generate podcast-like conversations between AI voices, providing human-like discussions of uploaded materials.
It supports a variety of content, as users can upload PDFs, text files, websites, and videos into "notebooks" to create customized summaries or ask questions about the content. In addition to audio overviews, NotebookLM provides study guides, accurate quotations, FAQs, and detailed summaries.
Furthermore, the first AI product creation platform was released by Arcade AI, described as “prompt-to-product” using design-to-manufacturing AI tech. It has a simple three step process where you enter a prompt, edit it, then share it with others. Currently, Arcade AI is in beta form.
Ai2's Multimodal Molmo Challenges Tech Giants
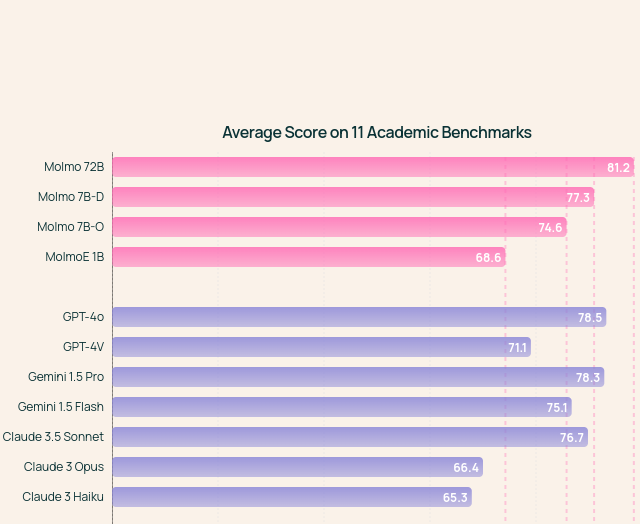
Molmo outperforms GPT-4o on academic benchmarks. (Source)
Ai2 launched Molmo, a multimodal open-source model that rivals major models like GPT-4o, Gemini 1.5, and Claude-3.5 in performance, but at a fraction of their size.
Molmo excels in tasks like answering questions about images, recognizing objects, and navigating web interfaces without needing complex infrastructure. This is thanks to the fact that it uses high-quality data, with only 600,000 annotated images, achieving impressive results compared to models trained on billions of images.
Replit's AI Agent vs Random Labs' IDE Integration
Replit’s new AI agent helps users build software projects from the ground up by using natural language prompts. As a result, it makes software development a lot more accessible to users of levels.
It’s available to Replit Core and Teams members at no additional cost during this “early access”, Pricing details will be available later in 2024 and it can be used through the web interface or mobile app.
Another agent release we saw was by Random Labs, who developed an AI agent directly integrated into the IDE. It can make changes across huge codebases and provides more than just autocomplete or chat functionality.
AlphaProteo's Protein Revolution and LIGO's Open-Source Leap
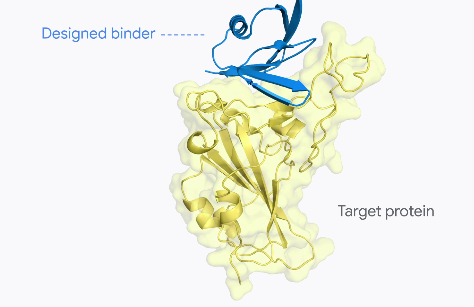
Predicted protein binder structure generated by AlphaProteo, shown in blue. (Source)
DeepMind made some significant advancements in biotech with the release of AlphaFold 3 a few months ago.
Now, they’ve developed a new AI system called AlphaProteo, which can design novel, high-strength protein binders to serve as building blocks for biological and health research. It aims to accelerate progress in areas like drug development, disease understanding, and biosensors.
The system generates new protein binders for diverse target proteins, including challenging targets like VEGF-A. It achieves higher experimental success rates and 3 to 300 times better binding affinities than existing methods on seven tested target proteins.
Sounds promising, but there’s still work to be done since the system has limitations like being unable to design binders for some challenging targets.
Speaking of AlphaFold 3, we saw an open-source implementation of it called LIGO. The current release implements the full AlphaFold 3 model along with the training code, focusing first on single chain prediction capability. Future updates will add ligand, multimer, and nucleic acid prediction capabilities once they are trained.
LIGO's implementation includes several core modules reused from the OpenFold project, such as triangular attention and multiplicative update, as well as their data processing pipelines. It also utilizes the ProteinFlow library for its data pipeline.
The project addresses some discrepancies from AlphaFold 3's published pseudocode, including changes to the MSA module order, loss scaling, and DiT block design.
OpenAI's GPT Next Bombshell: 100x Power, $2000 Price Tag
OpenAI Japan announced “GPT Next” - a model planned for release in 2024 and is supposed to be 100x more powerful than GPT-4. This name is just a placeholder though, and we’ve seen some rumors floating around that the model is codenamed “Project Orion” (funny how this has the same name as Meta's AR glasses project).
Orion focuses on improving NLP capabilities while expanding into multimodal territory, being able to integrate text, image, and video inputs. Notably, Orion is mentioned to leverage training data generated by O1, since high-quality data for training models isn’t always abundant.
It’ll be interesting to see if Orion will actually achieve such high performance as OpenAI claims, since training AI models on excess training data can actually lead to worse performance.
In terms of pricing, executives at OpenAI are even thinking about putting subscription prices as high as $2000 for access to models like O1 and Orion, a 100x price increase from ChatGPT subscription.
Anthropic also hit a milestone, with Anthropic’s Claude recently reaching $1 million in mobile app revenue. They’re going a step further with the release of Claude Enterprise.
It’s a new subscription plan for its AI chatbot aimed at enterprise customers, offering more administrative controls and increased security. Puts Anthropic in direct competition with OpenAI's ChatGPT Enterprise, which was released about a year ago.
ColPali and Qwen2-VL for Multimodal RAG and HoneyComb Takes Top Spot on SWE-Agent leaderboard
There was a recent discussion on X about ColPali being better for information retrieval over the combination of OCR and LLMs.
ColiPali and Qwen2-VL were used in combination. (Source)
ColPali is built on the PaliGemma-3B model, which we saw in an announcement at I/O 2024 by Google. In short, ColPali is a document retrieval model that uses VLMs to index and retrieve information from documents based on visual features.
The main aim is to tackle tricky issues that traditional document retrieval systems can’t deal with, like:
Complex data ingestion pipeline
OCR requirements
Difficulty in handling visual elements like tables and figures
A key benefit of using ColPali is that OCR or image captioning isn’t necessary. It’s also a more efficient method compared to OCR + LLMs while having higher accuracy. In addition, Qwen2-VL-7B is used for the generation process in RAG.
The Qwen2-VL models saw new releases last week with three sizes: 2B, 7B, and 72B, with the 7B instruction-tuned version being open-sourced.
It showed impressive results, achieving SOTA performance on visual understanding benchmarks like MathVista, DocVQA, and RealWorldQA. Moreover, it can understand videos over 20 minutes long for high-quality video-based tasks.
HoneyComb was a new model that took the SWE-Agent leaderboard by storm last week by achieving SOTA results, putting it in first place.
It takes a different approach to other models. Rather than having one, jack-of-all-trades AI agent, HoneyComb uses multiple AI agents that are fine-tuned to perform well at individual tasks like bug fixing and code review.
What’s great about this method is that it creates a potentially infinite cycle of continuous improvement and bug fixing. Makes the lives of software engineers easier by being able to automate any step of the development process.
A new feature for SQL query editing was another neat release. A bas this system executes queries in real-time as the user types them, so it provides instant feedback based on the query’s results and performance.
US, EU, and UK Sign Landmark COE Treaty on AI Safety, Draghis’ Report
Previously, the EU AI act came into force.
The saga continues as the Council of Europe (COE) has introduced the first-ever legally binding international treaty on AI safety, called the "Council of Europe Framework Convention on AI and Human Rights, Democracy, and the Rule of Law." Major signatories include the U.S., U.K., and European Union, along with several smaller nations.
The treaty focuses on three main areas:
protecting human rights (including data privacy and anti-discrimination)
Safeguarding democracy
Upholding the rule of law
Notable absences from the initial signatories include countries from Asia, the Middle East, and Russia. The treaty's goal is to create a technology-neutral framework that can withstand future developments in AI technology.
It’ll officially enter into force three months after at least five signatories, including three COE member states, have ratified it.
Draghi's report on European competitiveness came at a crucial time for AI regulation in the EU. It follows the recent implementation of the EU AI Act and the signing of the Council of Europe's landmark AI safety treaty.
While the treaty, which focuses on protecting human rights, safeguarding democracy, and upholding the rule of law, sets a broad regulatory framework, Draghi's report highlights the economic opportunities for the EU in the AI sector.
As the EU works to balance innovation with responsible AI development, Draghi's recommendations could inform how the EU implements the principles outlined in the COE treaty, especially in areas where Europe still has a competitive edge.
Plans for Two $125 Billion Supercomputers in North Dakota
We could see the development of two massive data centers in North Dakota, with each one costing up to $125 billion. This is currently being considered by two trillion-dollar market cap companies.
This means it's the usual suspects like Nvidia, Microsoft, Apple, and Google. Rumor has it that Microsoft might be a likely candidate since they were looking into building a $100 billion supercomputer campus with OpenAI in March 2024, which we talked about in our first newsletter.
The state currently has a small data center market, with only seven facilities listed.
Applied Digital, a cryptomining and AI provider, recently secured $200 million for facility expansion in the state and has a deal with an unnamed hyperscaler. Also worth pointing out that the state produces more energy than it uses.
Advancements in AI Research
Midjourney’s competitor FLUX saw some interesting developments from the research side of things, with a new paper detailing a generative framework called FluxMusic for text-to-music generation. In addition, we got some insights into new approaches for training LLMs with long context windows and improving traditional RAG methods.
Composing the Future of AI-Generated Soundscapes With FluxMusic
We talked about Black Forest Lab’s FLUX before and noted that it’s a pretty serious competitor for Midjourney.
This paper gives us a new approach to text-to-music generation that aims to strengthen multimodal LLM perception and support higher input resolutions, with FluxMusic being a generative framework.
It handles the issue of creating more versatile and powerful AI systems capable of generating high-quality music from textual descriptions, a task that has long been limited by the complexity of musical structure and the need for domain-specific knowledge.
They implemented a two-tiered LLM chain for content refinement and information extraction, and utilized multiple pre-trained text encoders for conditioned caption feature extraction and inference flexibility.
FLUX models support input resolutions up to over 1000 pixels and achieve strong performance on multimodal LLM benchmarks. This is especially true for resolution-sensitive tasks like OCR and document understanding. Notably, FLUX outperformed other prominent models like Mini-Gemini-HD and LLaVA-NeXT across various metrics.
Breaking the Long Context Barrier
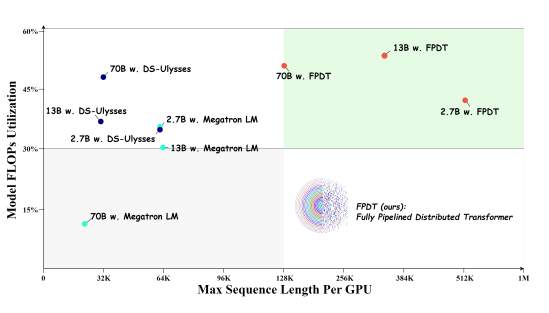
End-to-end model training comparison. (Source)
Researchers from Ohio State University and Microsoft have introduced a novel approach to training LLMs with extremely long context windows.
Current LLM training is typically constrained to relatively short context lengths, such as 8K or 32K tokens, limiting their ability to process entire documents or maintain coherent long-term dialogues.
They introduced the Fully Pipelined Distributed Transformer (FPDT) that leverages multiple memory hierarchies in modern GPU clusters to enhance hardware efficiency and cost-effectiveness.
This method uses:
A chunking mechanism
Offloading idle tokens to host memory
A double buffer strategy to overlap computation with data transfer.
FPDT can train an 8B parameter LLM with a 2 million token context length using only 4 GPUs, achieving over 55% Model FLOPs Utilization (MFU). This represents a 16x increase in sequence length compared to current SOTA solutions while maintaining high efficiency.
How 16K Tokens of RAG Outperform 128K Context LLMs
As long-context language models (LLMs) become increasingly prevalent, some have questioned the continued relevance of RAG. A new study from NVIDIA researchers challenges this notion by showing that RAG still has a crucial role to play, even in the era of models with 100K+ token contexts.
The team introduces Order-Preserve RAG (OP-RAG), which significantly improves upon traditional RAG methods. By maintaining the original order of retrieved chunks rather than sorting by relevance, OP-RAG achieves a better balance between information recall and precision.
They found that as the number of retrieved chunks increases, answer quality follows an inverted U-shaped curve, with an optimal "sweet spot" that outperforms long-context LLMs using the entire available context.
Results on the ∞Bench dataset are striking: OP-RAG using Llama3.1-70B with just 16K retrieved tokens achieved a 44.43 F1 score, surpassing the 34.32 score of Llama3.1-70B using its full 128K context. It even bested GPT-4o (32.36) and Gemini-1.5-Pro (43.08).
Frameworks We Love
Some frameworks that caught our attention in the last week include:
Anthropic Quick starts: Collection of ready-to-use projects designed to help developers quickly build deployable applications using the Anthropic API and Claude's capabilities.
LLM-CI: Assesses privacy norms encoded in LLMs using a Contextual Integrity-based factorial vignette methodology across different contexts.
GetOmni AI: Open-source OCR tool that uses GPT-4 vision models to convert PDF documents into high-quality markdown text.
Conversations We Loved
One discussion raised the question of what led to public cloud storage prices plateauing in 2017 rather than continuing to decrease like earlier years.
The Great Cloud Storage Plateau
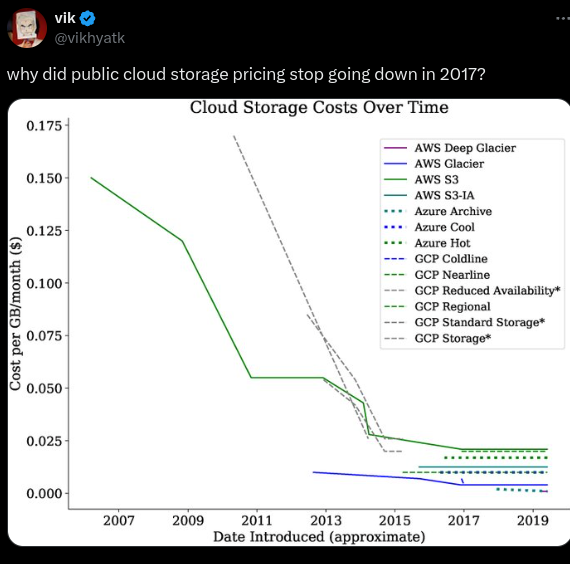
Cloud storage costs from 2007 to 2017. (Source)
A graph that tells a fascinating story about the evolution of cloud storage pricing caught our eye. The image, which tracks the cost per GB/month across various cloud providers from 2007 to 2019, reveals that after years of steep declines, prices seemed to hit a floor around 2017.
This plateau in cloud storage costs makes us wonder about the economics of cloud computing and the broader tech industry.
Some speculate that we've reached the physical limits of storage density improvements, while others point to market consolidation and reduced competition. There's also the possibility that cloud providers have shifted their focus from raw storage to value-added services.
Money Moving in AI
A couple of huge acquisitions and investment rounds took place last week, with SSI raising $1 billion and Salesforce purchasing Own for $1.9 billion. You.com also raised $50 million from a series B funding round.
Ilya Sutskever Raises $1 Billion for New AI Safety Startup
Just a few months ago, OpenAI disbanded its AI safety team and key members left the company, including Ilya Sutskever. Sutskever created his own AI safety startup which raised a staggering $1 billion at a $5 billion valuation, just three months after its founding.
You Raises $50 Million in Series B Funding
You.com, an AI search company focusing on complex queries and productivity tools, has raised $50 million in a Series B round led by Georgian, with participation from notable investors including Nvidia and Salesforce Ventures.
The company is betting on its ability to excel at answering complex questions and providing a "productivity engine" for knowledge workers.
Salesforce Acquires Own for $1.9 billion
Salesforce made its largest acquisition since Slack, purchasing data management firm Own for $1.9 billion in cash. The deal highlights the growing importance and value of data protection and management solutions in the enterprise space, with the global data backup and recovery sector worth $12.9 billion in 2023.