- GenAI360 - Weekly AI News
- Posts
- More Accurate Knowledge Retrieval for Scientific Research, Healthcare & Drug Discovery LLMs, 10x LLaMa3’s Context
More Accurate Knowledge Retrieval for Scientific Research, Healthcare & Drug Discovery LLMs, 10x LLaMa3’s Context
DeepMind's Med-Gemini outperforms GPT-4, cloud infrastructure company secures $1.1 billion, LLaMa3's context increased by 10x overnight

Before we start, share this week's news with a friend or a colleague:
Key Takeaways
This week’s key developments include:
Flagship Pioneering, a biotechnology company that invents platforms and builds companies that change the world (portfolio companies include Moderna and Inari Agriculture) achieves 18% increase in RAG accuracy for scientific research together with Activeloop.
Major AI advancements in biotech with the release of LLaMa3-OpenBioLLM, Balto, and DeepMind’s MedGemini boost medical research capabilities.
Nvidia ChatRTX expands its model support, incorporating Google’s Gemini and OpenAI’s CLIP for better personal document and photo querying.
New dataset GSM1k reveals potential overfitting in current LLMs when compared to traditional benchmarks.
LLaMa3’s context was expanded from 8000 to 80,000 tokens in just 8 hours on a single machine and performed well at long-context evaluation tasks.
The introduction of Kolmogorov-Arnold Networks (KANs) promises a shift in neural network architectures, with better performance and fewer parameters.
Got forwarded this newsletter? Subscribe below 👇
The Latest AI Scoop: How Flagship Pioneering Makes Big Leaps in Biotech with Retrieval Augmented Generation
Learn how Flagship Pioneering & Activeloop are advancing retrieval augmented generation in biotech with a novel retrieval system for multi-modal biomedical data
Flagship, and its Pioneering Intelligence (PI) initiative, as well as Activeloop embarked on a collaboration to solve a challenge. How can one efficiently answer complex scientific questions by searching through large-scale, multi-modal data without compromising accuracy or adding complexity? This is where Activeloop's solutions made a difference.

Multi-layered solution developed with the support of Intel RISE & Disruptor Initiatives
Together, Pioneering Intelligence and Activeloop formed a research partnership to address these needs. PI developed systems to generate and evaluate query-retrieval pairs at scale across a diverse range of biological topics. These queries were designed to reflect more “realistic” questions that Flagship might pose during scientific exploration. Activeloop provided Deep Lake, the database for AI, and a capability called Deep Memory. Deep Memory increases retrieval accuracy without impacting search time with a learnable index from labeled queries tailored to a particular RAG application.
With Deep Lake and Deep Memory, Flagship Pioneering has found a way to significantly improve the process of retrieving accurate data, leading to an 18% increase in accuracy compared to traditional methods, streamlining drug discovery research and development process.
The Latest AI News
Biotech took the spotlight this week with some technical advancements in knowledge retrieval including Activeloop Deep Lake's success with Flagship Pioneering and Intel, and major model releases like OpenBio LLaMa3, MedGemini, and Balto.
We also saw that tech giants Microsoft and OpenAI are currently facing a lawsuit due to the training data they used.
Major AI Releases in Biotech
Saama AI Research Labs introduced the LLaMa3-OpenBioLLM models with 8B and 70B versions. The 70B model is a high-performance biomedical LLM designed for medical and life science use. It builds on the Meta-LLaMa3-70B-Instruct model by using high-quality biomedical data for fine-tuning.
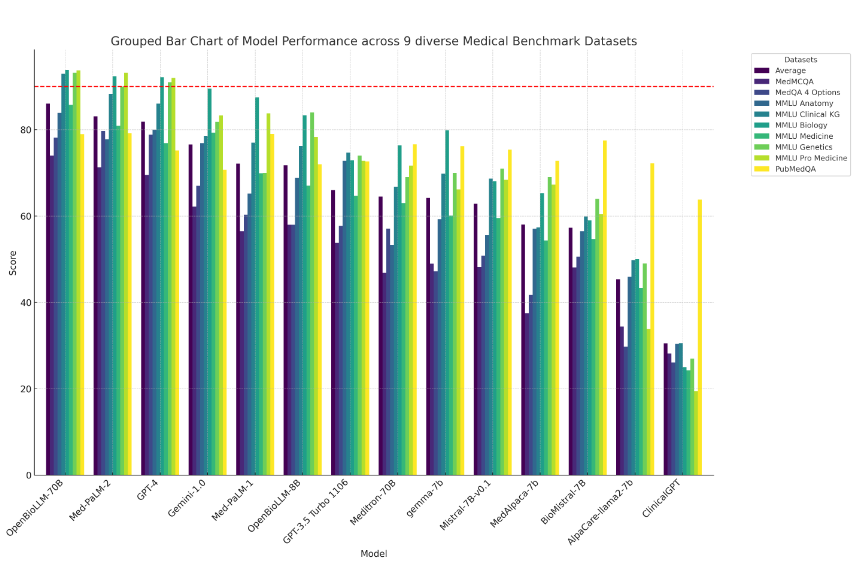
Comparison of model performance across nine medical benchmarks. (Source)
These models showed impressive performance on medical benchmarks like MMLU Genetics and MMLU Pro Medicine, making them suitable for tasks like:
Clinical note summarization
Medical question answering
Entity recognition
This makes it highly valuable for improving medical documentation and diagnosis support.
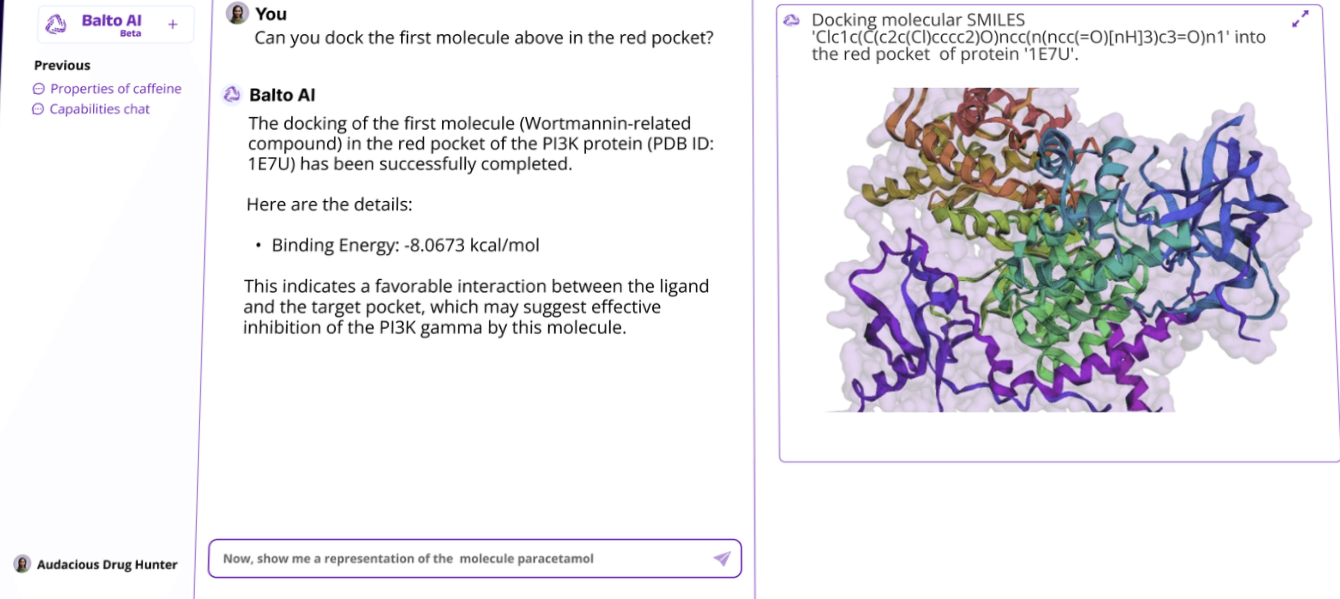
An example of Balto performing docking. (Source)
Balto was another AI release in the biotech space, an AI assistant tailored for drug discovery by using state-of-the-art computational tools.
It can perform tasks like:
Docking
Predicting molecular properties
Simulating protein-ligand properties
Moreover, Balto provides an intuitive interface that simplifies complex simulation and analysis tasks. It’s an important release because it increases the precision and speed of drug discovery workflows - not to mention that its performance on benchmarks like PDBBind adds to its credibility.
Nvidia Boosts Chatbot Support and Introduced New Models
Nvidia’s ChatRTX is a chatbot for RTX GPU owners. The AI model support will be expanded by including Google’s Gemini and OpenAI’s CLIP, improving its capability to query personal documents and search photos.
This support will also include ChatGLM3, a bilingual LLM that will add versatility by supporting English and Chinese. New voice query functionality is also included through the integration of Whisper, an AI speech recognition system.
Nvidia also introduced new LLaMa3-ChatQA-1.5 models, including 8B and 70B versions that specialize in conversational question answering and retrieval-augmentation generation.
Both models showed superior performance on various benchmarks, such as Doc2Dial and HybriDial. As a result, these models offer more nuanced and context-aware interactions, which makes them applicable across various industries, from customer service to tech support.
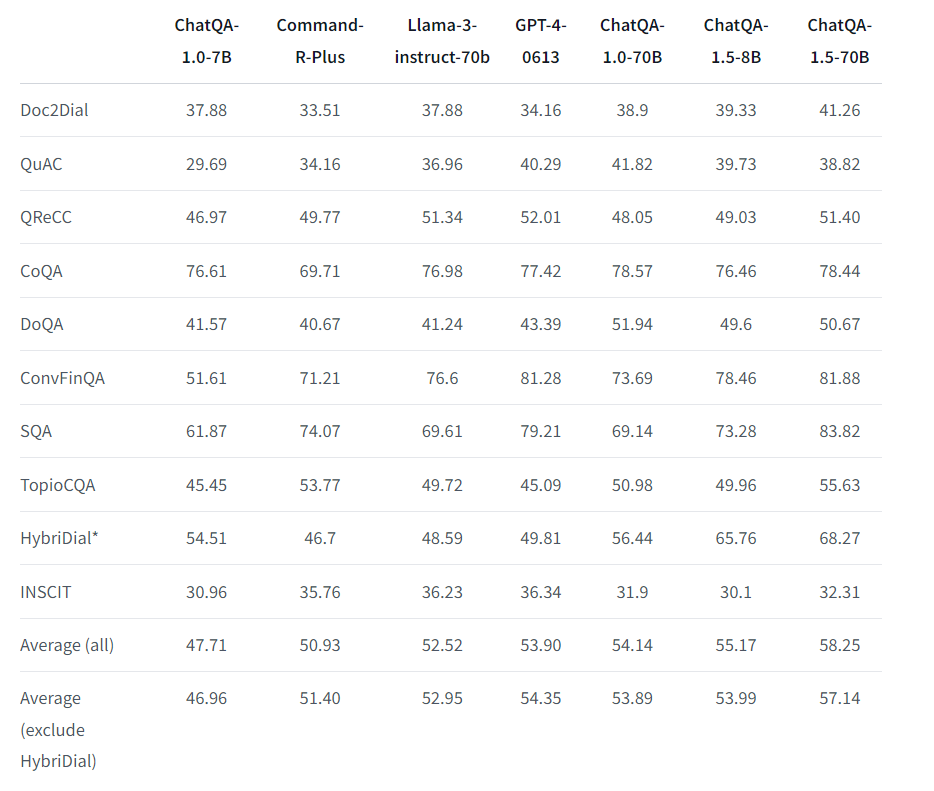
Table comparing the performance of various AI models across multiple question-answering benchmarks. (Source)
Meta Plans $800 Million Data Center While Microsoft and Tech Giants Face Issues With Limited Training Data and Lawsuits
Major tech firms Google, Microsoft, and Meta face challenges due to the limited availability of high-quality organic data. Their solution is to use more synthetic data for training - a tempting option since generative AI can quickly generate synthetic data at scale.
Meta also plans to build a new $800 million data center in Alabama to support 100 operational jobs. The data center is expected to be operational by the end of 2026 and powered entirely by renewable energy, highlighting Meta’s shift toward more sustainable technology infrastructures.
On the flip side, eight newspapers owned by Alden Global Capital filed a lawsuit against OpenAI and Microsoft. The lawsuit accuses the tech giants of using millions of copyrighted articles to train their AI products like ChatGPT without permission. While OpenAI claimed to be unaware of the claims, Microsoft declined to comment entirely.
New Releases to Boost Team Collaboration by Anthropic and Atlassian
Anthropic made its move in the mobile space by releasing a new iOS app and Team plan for its AI platform Claude - improving functionality for team collaboration.
The team plan costs $30 a month and requires a minimum of five seats. It offers extensive chat capabilities and integrates seamlessly with the web platform, supporting features like photo uploads and real-time image analysis.
Atlassian also released a new AI assistant called Rovo during its Team ‘24 conference with a similar goal in mind to Anthropic - improving team collaboration and productivity. It integrates AI-powered search tools and workflow automation using Rovo agents. These agents can be built using a natural language interface without any programming skills.
Advancements in AI Research
AI in biotech saw more model releases, with DeepMind releasing MedGemini models that performed well in various medical benchmarks, such as MedQA.
Other key research advancements include the introduction of a method to extend the context length of LLaMa3-8B-Instruct by 10x overnight and a new neural network architecture called Kolmogorov-Arnold Networks (KANs).
Extending LLaMa3’s Context 10x Overnight
Researchers in China presented a method to extend the context length of the LLaMa3-8B-Instruct model from 8000 to 80,000 tokens using QLoRA fine-tuning. This was achieved with only 3500 synthetic training samples using GPT-4.

Comparison of evaluation results on LongBench. (Source)
What’s impressive is that the training process required only 8 hours on a single machine with 8xA800 GPUs, making it a very practical approach for scaling LLMs. It’s a big improvement over previous techniques that required considerable compute and time.
The extended context model showed superior performance across various long-context evaluation tasks, such as NIHS and topic retrieval, while maintaining its capability in shorter contexts.
DeepMind’s Med-Gemini Models for Medical Applications
DeepMind researchers introduced Med-Gemini, a family of multimodal models specialized for medical applications, by building upon the Gemini model architecture.
These models incorporate:
Clinical reasoning
Multimodal understanding
Long-context processing
This paper is important because the Med-Gemini models achieved state-of-the-art results on 10 out of 14 medical benchmarks, surpassing models like GPT-4 in both specific medical tasks and general capabilities.
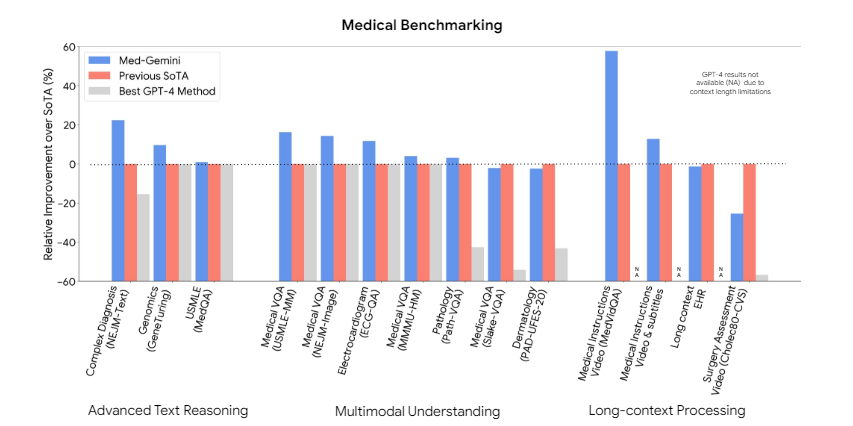
Comparison of MedGemini against GPT-4 in various medical benchmarks. (Source)
Not only that, but Med-Gemini showed real-world utility by outperforming human experts in tasks like medical text summarization and generating referral letters. It also showed promising applications in multimodal medical dialogues and medical evaluation.
A Better Alternative to MLPs?
This paper introduces Kolmogorov-Arnold Networks (KANs) - a novel neural network architecture inspired by the Kolmogorov-Arnold representation theorem.
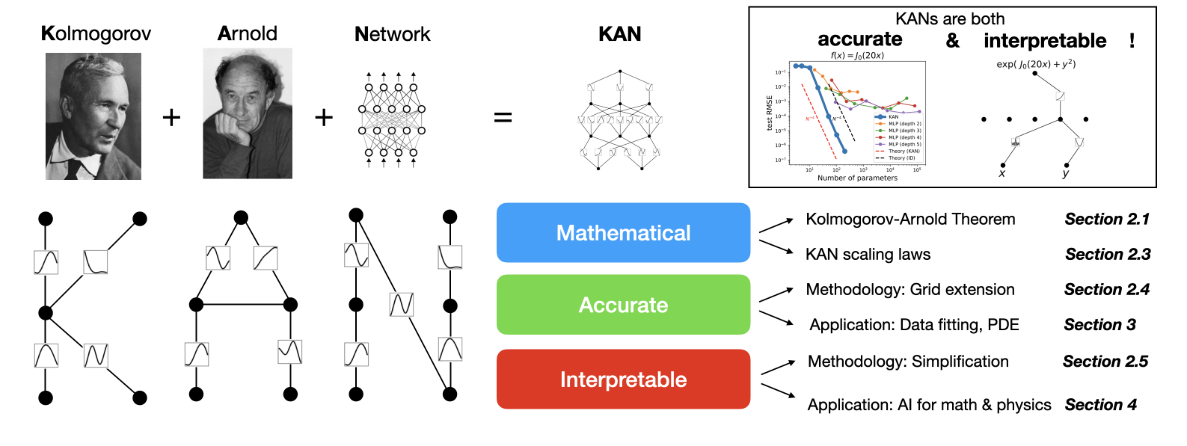
KANs overview. (Source)
Learnable activation functions on the network edge replace traditional linear weights in Multi-Layer Perceptron's (MLPs - a type of feedforward neural network consisting of fully connected neurons with a nonlinear kind of activation function).
Unlike MLPs that use fixed activation functions, KANs incorporate adjustable activation functions, improving model accuracy and interpretability. This was particularly true for tasks like data fitting and solving partial differential equations.
KANs also showed better performance with significantly fewer parameters and faster training than traditional MLP architectures, a major advancement in making deep learning more accessible and sustainable.
Examining LLM Performance
A new dataset called Grade School Math 1000 (GSM1k) was introduced. It’s designed to evaluate the reasoning ability of LLMs without the potential bias of existing training datasets like GSM8k, which might be affected by contamination.
This paper evaluates several open-source and closed-source LLMs on the GSM1k and shows a performance drop of up to 13% compared to GSM8k. It highlights issues like potential overfitting or memorization in current LLM benchmarks.
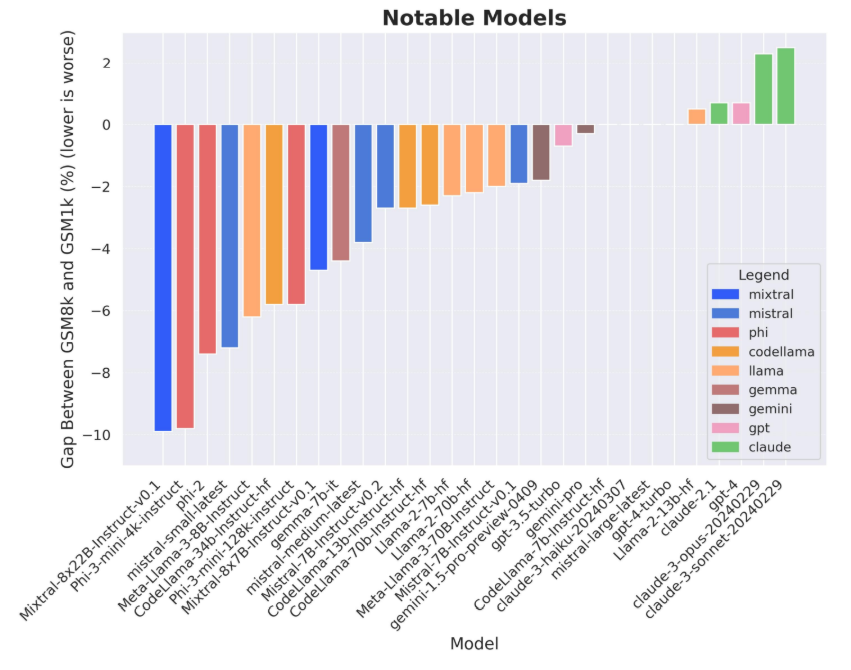
Comparison of various LLMs performance drops when using GSM1k. Mistral-8x22B and Phi-3 Mini suffered the most from overfitting, with almost 10% performance drops. (Source)
Despite the performance drop, even the most overfit models can still solve new problems correctly.
Projects We Love
Highlight: How to Build a RAG Data Engine

We spoke at AI User Group meetup on why RAG isn't enough for accurate retrieval
Davit, our CEO, was hosted by kind people at AIUserGroup on using a combination of fine-tuning, RAG, and advanced retrieval methods like Deep Memory (that's in production with companies like Flagship Pioneering) to boost the performance of Llama-3 family of models. Tune in to here more and hit us up if you'd like an access to the system we're building!
Some frameworks that caught our attention in the last week include:
StoryDiffusion: Improves the generation of consistent images and video from text generation.
LLM security guard: Integrates static code analyzers with LLMs to identify and resolve security vulnerabilities in generated code.
ASAM: An enhancement to the Segment Anything Model (SAM) by Meta AI designed for image segmentation.
If you want your framework to be featured here, get in touch with us.
Conversations We Loved This Week
This week, a couple of interesting discussions came up, including the CUDA/C++ roots of deep learning and fine-tuning embeddings.
Deep Learning Origins
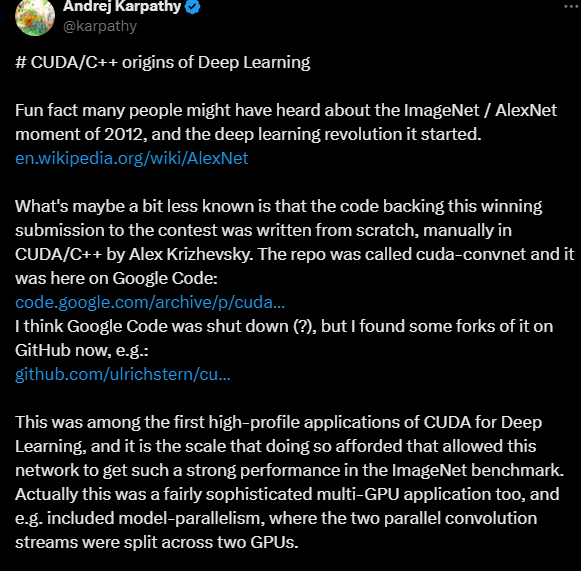
Karpathy’s discussion of the origins of deep learning. (Source)
Karpathy mentions that the original code that Alex Krizhevsky wrote for the AlexNet in CUDA/C++ was one of the first significant uses of CUDA for deep learning. At the time, deep learning was mainly done in MATLAB on CPUs, so this approach of using a normal ConvNet on a GPU was groundbreaking.
The success of AlexNet proved the effectiveness of scaling up simple architectures, which went against the main focus of complex algorithms. The implementation was advanced at the time since it used multi-GPU capabilities with model parallelism across two GPUs for enhanced performance.
It was an important development for shifting focus toward scaling up neural networks using GPUs. Moreover, AlexNet’s success accelerated interest and development in frameworks that could leverage GPU computing.
Karpathy’s initial post led to a heated debate between Yann LeCun and Jeff Dean. LeCun initially misunderstood references to DistBelief, thinking it was only about the ICML 2012 “cat detector” paper and not recognizing its broader use when describing it as a “dead end”.

Dean’s reply to LeCun. (Source)
Outperforming OpenAI With Limited Training Data
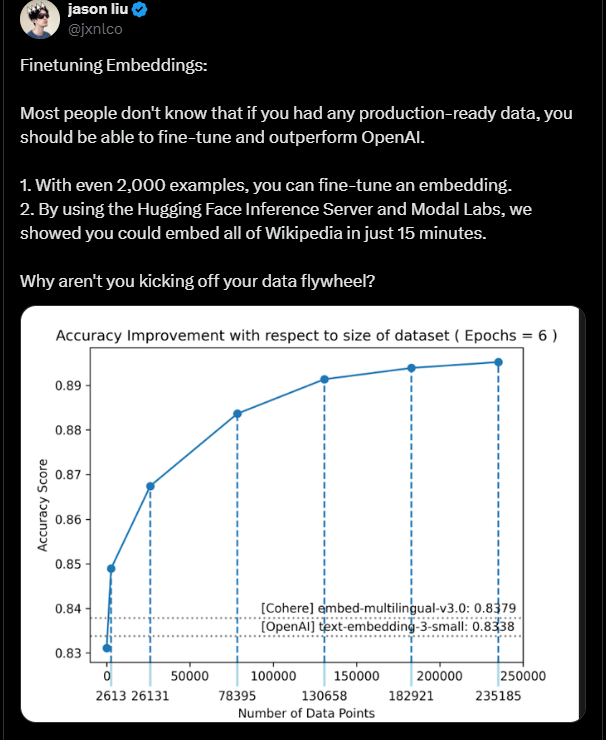
Liu’s comments on fine-tuning embeddings. (Source)
Jason Liu, Ivan Leo, and Charles Frye conducted an experiment to show that fine-tuning an open-source model with a small dataset can surpass the accuracy of proprietary models like OpenAI’s text embeddings.
The experiment used a modest number of examples to achieve better performance in textual similarity tasks, highlighting the reduced operational costs of using open-source models with serverless infrastructure.
It shows that even limited datasets can drastically boost model accuracy, going against the common belief that you always need vast data for high performance.
Fundraising in AI
Nvidia continues its hot streak in the AI space by acquiring AI startup Deci just after it acquired Run.ai last week.
CoreWeave also saw success by securing $1.1 billion, while Lamini raised $25 million from investors like Andrew Ng and Dropbox CEO Drew Houston.
CoreWeave Secures $1.1 Billion in Series C Funding
CoreWeave, a specialist in AI-focused cloud infrastructure, has secured $1.1 billion in Series C funding, led by firms like Coatue and Magnetar. The funding will be used to expand CoreWeave’s operations into new markets and meet global demand for specialized AI cloud services.
Lamini Raised $25 Million
A startup called Lamini is creating a generative AI platform for enterprises. It has raised $25 million from notable investors, including:
Stanford professor Andrew Ng
Figma CEO Dylan Field
Dropbox CEO Drew Houston
Former Tesla and OpenAI researcher Andrej Karpathy
The funding will help expand Lamini’s team, enhance technical infrastructure, and further develop their platform.
Nvidia Acquired Deci for $300 Million
Nvidia purchased AI startup Deci for $300 million, boosting its AI capabilities. This acquisition is part of Nvidia’s broader strategy to expand its AI portfolio, seen in its purchase of Run.ai last week for $700 million.