- GenAI360 - Weekly AI News
- Posts
- LLaMa-3 & Microsoft's Phi Top the Charts, New Transformer Architecture is All We Need?
LLaMa-3 & Microsoft's Phi Top the Charts, New Transformer Architecture is All We Need?
Cloud vs on prem trends, toxic Wizards from Microsoft, and more

Key Takeaways
Meta's LLaMa-3, leveraging Chinchilla scaling laws, features a 128,000 token vocabulary and is trained on 15 trillion tokens, which significantly improves its performance across major benchmarks like MMLU and HumanEval.
Microsoft introduced three new AI models: the compact Phi model family to rival Gemini and GPT-3.5, VASA-1 for creating life-like talking videos, and WizardLM-2, which was temporarily pulled due to a lack of toxicity testing.
Boston Dynamics unveiled a new version of the Atlas robot with enhanced mobility and human-like capabilities.
Google introduced mobile device processing advancements and a new transformer architecture called TransformerFAM.
UAE-based AI firm G42 received a massive $1.5 billion investment from Microsoft, and Perplexity's now a unicorn.
The Latest AI News
We saw promising LLM releases, like Meta's LLaMa-3, Phi, and Reka Core. Microsoft has also been the talk of the week by introducing three new AI models, one of which had to be pulled because of a lack of toxicity testing.
On the flip side, AI wearables saw two new releases, but one… flopped.
Compared to other AI newsletters, how much do you enjoy reading our newsletter?Be honest :) |
Meta’s Latest LLM: LLaMa 3
Meta launched LLaMa-3, an advanced open-source LLM with 8B and 70B parameter versions is the new king of open-source models. It is currently #5 in the Arena leaderboard, with 400B version still in training.

Arena results
Some of the key improvements from its predecessor LLaMa 2 include:
Expanded 128,000 token vocabulary: More than 4x larger than the 32,000 token vocabulary of LLaMA-2.
Trained on 15 trillion tokens: Over 7x more data than the 2 trillion tokens used for LLaMA-2.
Increased context length: 8,192 tokens, which is double the 4,096 context of LLaMA-2.
Leverages Chinchilla scaling laws: To get a bang for your buck in LLM training, you should follow Chinchilla scaling laws (log-linear performance gains as model size increases). For a 8B parameter model, 15T is an immense dataset (~200B tokens would be the optimum, so it's 75x more than necessary). As a result, you get a very capable model that is very small, easy to work with and inference.
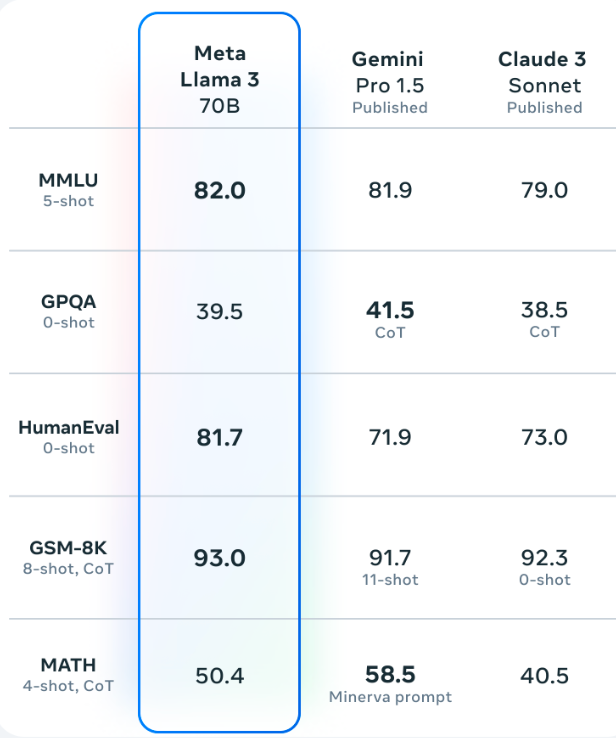
LLaMa 3 outperformed Gemini Pro 1.5 and Claude 3 Sonnet across various benchmarks like HumanEval, MMLU, and GSM-8K. (Source)
Despite this extensive training, LLaMa 3 hasn’t reached a point of convergence.
LLaMa 3’s continued adaptability suggests that even with 15 trillion tokens, the model shows potential for further learning and refinement.

Karpathy’s comments on Meta’s LLaMa 3. (Source)
Microsoft’s New Models: VASA-1, Wizard-LM2, and Phi
Couple of days after Llama, Phi-3 AI family of small language models was released. Similar to Google's release of Gemini, it comes in three sizes - 📍Mini (3.8B), Small (7B), and Medium (14B parameters). The compact 3.8B-parameter language model that rivals the capabilities of larger models like Mixtral 8x7B, GPT-3.5, and even newly released Llama-3 8B. It's trained on 3.3 trillion tokens (a mix of heavily filtered and synthetically generated data), is small enough to be deployed on smartphones, such as the iPhone 14, where it can generate over 12 tokens per second

Performance against benchmark tasks of the Phi family of models
Microsoft also introduced a new model called VASA-1, which creates life-like talking head videos from a single photo and audio sample. Notably, the results are impressive, with realistic lip-sync and head movements.
Although VASA-1 could be applied to video games, social media avatars, and AI-driven filmmaking, it’s currently a research tool without any plans for public release just yet.
Microsoft also released Wizard-LM2 but quickly pulled it offline due to a lack of toxicity testing. The model was uploaded to GitHub and Hugging Face before being deleted.
Developers apologized and announced plans to complete the needed testing to re-release the model.
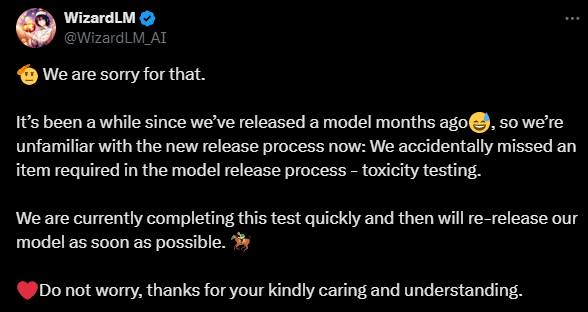
WizardLM-2 developer’s statement on the situation. (Source)
Updates in AI Wearables
Rewind pivoted from a personal data recording service to a new brand called “Limitless”, focusing on an AI-powered meeting suite and a conversation-recording pendant.
The pendant is designed to record and transcribe conversations, making it particularly useful for meetings. What’s more is that the Limitless pendant is weather-proof and has a 100-hour battery life. While the Limitless Pendant is great for transcribing conversations, the Rabbit R1 has broader applications because of its web interaction capabilities.
Sam Altman-backed Humane AI released its Ai Pin product but quickly gathered negative reviews. Specifically, Marques Brownlee published a new video called “The Worst Product I’ve Ever Reviewed…For Now”, which mentioned how slow the device was and its low battery life. The device has a price tag of $699 + a $24 per month subscription.
Altman is also planning to start a new company focused on producing an AI-powered personal device with former Apple design lead Jony Ive and is currently in the process of seeking $1 billion in funding.
The Latest Version of the Atlas Robot

The new Atlas robot. (Source)
Boston Dynamics unveiled a new version of its Atlas robot, transitioning from a hydraulic to an all-electric design for better mobility and flexibility.
The new robot has features like swivelling joints, longer limbs, a straighter back, and a distinctive head with a built-in ring light. As a result, it offers more human-like and complex movements compared to previous versions.
Boston Dynamics plans to test the new Atlas with a select group of customers, such as Hyundai while continuing to develop its functionality for various industrial applications.
A New Startup to Challenge GPT-4?
San Francisco-based AI startup Reka released Reka Core, a multimodal language model that is competitive with top LLMs, such as GPT-4 and Claude 3 Opus.
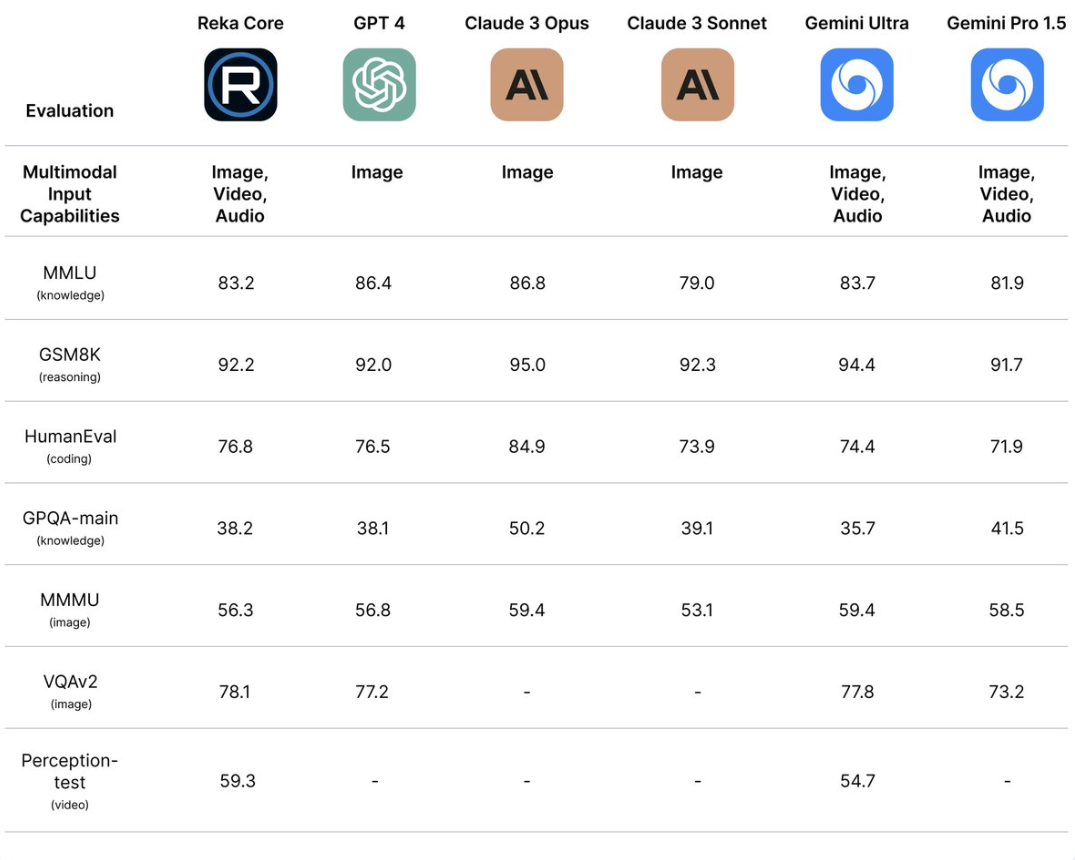
Reka Core shows impressive performance across various benchmarks, outperforming GPT-4 in GSM8K and HumanEval. (Source)
Cloud Computing Trends
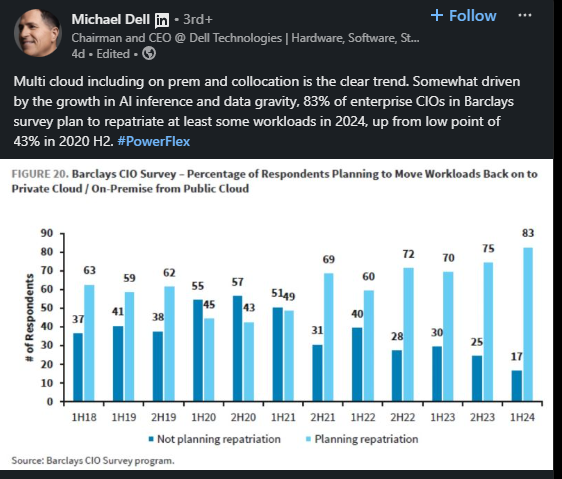
Dell’s comment on recent cloud computing trends. (Source)
Michael Dell pointed out an important trend among enterprises regarding their strategies for managing cloud computing and data handling.
Businesses are adopting a multi-cloud strategy that includes on-premise data centers and colocation facilities. Dell also mentioned that 83% of Chief Information Officers (CIOs) surveyed by Barclays plan to move at least some of their cloud-based workloads back to on-premise or private cloud environments in 2024.
This is a significant increase from 43% in the second half of 2020, which might show growing concerns with the limitations or costs of public cloud services alone.
Advancements in AI Research
Thanks to Google, AI research saw important progress this week, especially in the mobile device and transformer architecture space.
Mobile Device Processing Advancements
Google has made big advancements in the mobile device space with MobileNetV4, a model suite that features the Universal Inverted Bottleneck (UIB) and Mobile MQA blocks for enhanced performance.
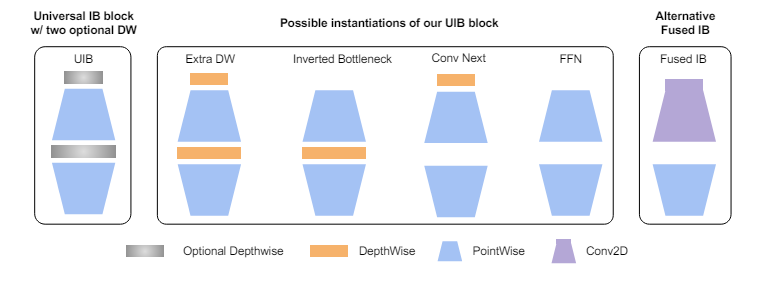
UIB blocks for network design. (Source)
MobileNetV4 includes variant models optimized for different hardware, which resulted in high performance. One example is the MNv4-Hybrid-L model, which reached 87% top-1 accuracy on ImageNet-1K.
Additionally, the paper introduced a new distillation technique that boosts accuracy by leveraging diverse datasets and novel augmentation techniques.
New Transformer Architecture
Google released a new paper detailing a new transformer architecture called TransformerFAM. This architecture integrates a feedback loop, allowing the network to attend to its latent representations.
It aims to handle infinitely long sequences more effectively by overcoming the limitations of traditional Transformers, which struggled with quadratic complexity in attention mechanisms.
The paper presented experimental results that showed TransformerFAM outperforms existing models on long-context tasks, highlighting its ability to manage longer sequences and maintain context over extended periods.
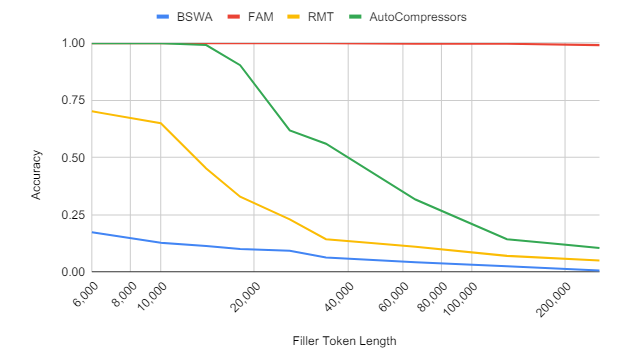
TransformerFAM achieves higher PassKey Accuracy than other methods. (Source)
Image Signal Processing With Global Context Guidance
This paper focuses on enhancing Image Signal Processors (ISP) with deep learning techniques to process RAW images into high-quality RGB outputs.

Example of how ISP can improve image quality. The top image is the Huawei P20 ISP, while the bottom is the proposed SimpleISP neural network. (Source)
It proposes a novel module called Color Module (CMod), which integrates the global context of RAW images into the processing. As a result, it helps overcome the limitations of patch-based training (a widespread technique in image processing) that would typically miss this context.
In addition, the model was tested on new datasets created by the authors and showed better performance in converting RAW smartphone images to DSLR-quality RGB images. It achieved state-of-the-art results by outperforming existing models regarding image quality on various benchmarks.
Integrating LLMs Into Data Interaction Tasks With DB-GPT
This paper presents an open-source Python library named DB-GPT, which improves data interaction tasks using a multi-agents framework and a privacy-sensitive setup. DB-GPT provides natural language interfaces for databases.
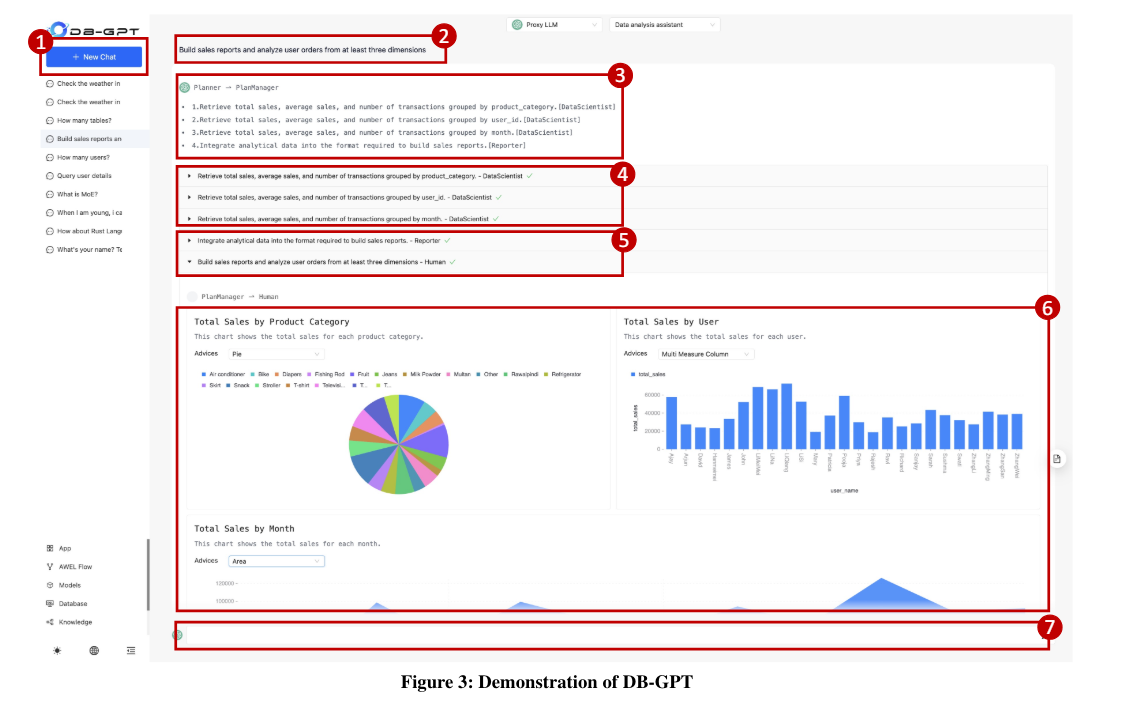
DB-GPT demonstration. (Source)
Moreover, the paper introduces a new declarative language called the Agentic Workflow Expression Language (AWEL) to help users arrange the workflow of multi-agents flexibility with minimal coding.
DB-GPT supports a wide range of data interaction functionalities, including:
Text-to-SQL
SQL-to-Text
Generative data analysis
Multilingual capabilities
Frameworks We Love
Some frameworks that caught our attention in the last week include:
Code Interpreter: Creates custom code interpreters for any LLM by E2B.
Prediction Guard: Safeguards AI interactions with advanced privacy protocols and precise output validation.
LLM-ADE: Enhances the training and adaptability of LLMs by overcoming issues like double descent and catastrophic forgetting.
If you want your framework to be featured here, get in touch with us.
Conversations We Loved This Week
Another week, another story of AI controversy in the creative industry.
But this time, it’s Netflix currently under fire for using AI-generated images in a documentary.
Other than that, Sebastian Raschka provided an interesting discussion about a new paper that finally compares DPO and PPO for LLM alignment.
Netflix Uses AI-Generated Images in Documentary
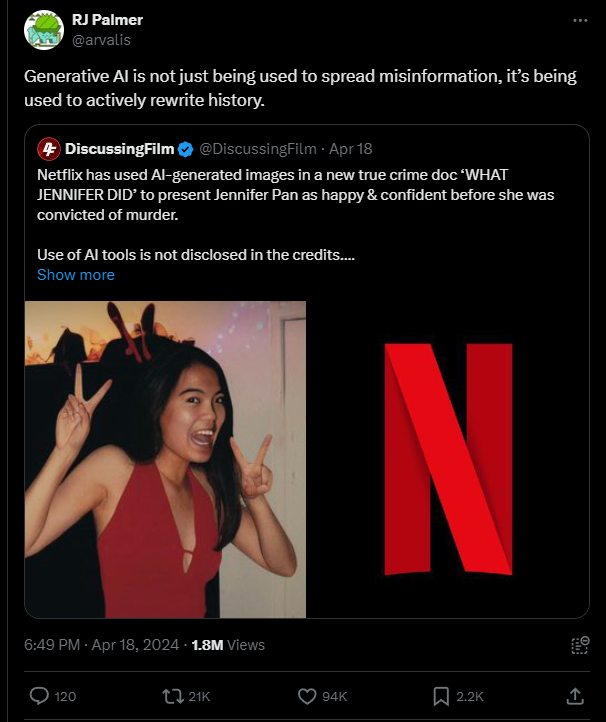
RJ Palmer’s comment on the use of AI in a Netflix documentary. (Source)
AI in the creative industry continues to be a hot topic, with Netflix taking the heat this time.
They were accused of using AI-manipulated images in the true crime documentary “What Jennifer Did”, which explores the case of Jennifer Pan - convicted in a kill-for-hire attack on her parents.
Viewers noticed anomalies in multiple images featured in the documentary, where images of Pan had misshapen hands and other strange features.
This causes problems for various reasons. Namely, a true crime documentary is expected to be factually accurate, especially considering that it’s dealing with a sensitive topic.
Palmer raised concerns that AI is being used to alter historical narratives rather than just spread misinformation. Consequently, it affects how future generations understand past events and can lead to forms of revisionism in which certain events are exaggerated or even omitted entirely.
DPO and PPO Comparison for LLM Alignment

Raschka’s post about a recent paper looking at DPO and PPO. (Source)
A new paper comparing Direct Policy Optimization (DPO) and Proximal Policy Optimization (PPO) in the context of LLM alignment.
He mentions DPO has gained popularity as a simpler alternative to PPO in Reinforcement Learning from Human Feedback (RLHF) because a separate reward model isn’t needed.
Raschka notes the paper presents the first direct comparison of the same model trained using both PPO and DPO on the same dataset—an important analysis that hasn’t been done yet.
Additionally, the results showed that PPO outperforms DPO in most cases, especially when handling out-of-distribution data, which is essential for the robustness of LLMs.
Fundraising in AI
GenAI Search startup Perplexity hit a unicorn status, G42 saw a massive $1.5 billion investment from Microsoft this week, while other companies like Rivos and Avilogic were also successful in their funding efforts.
Perplexity's a Unicorn After Today's $63M Injection
Perplexity, an AI search startup challenging Google, has raised $63 million in a new funding round, valuing the company at $1 billion. The round was led by Daniel Gross and included notable investors such as Stanley Druckenmiller, NVIDIA, Jeff Bezos, Garry Tan, Andrej Karpathy, Tobi Lutke, and others.
G42 Receives $1.5 Billion Investment From Microsoft
Announcing two new models wasn’t the only big move Microsoft made this week.
They also announced a massive $1.5 billion investment in G42, a large AI firm based in the UAE, as part of their strategic efforts to expand their global presence in the AI sector globally.
The new partnership with Microsoft includes shifting G42’s AI services to Microsoft’s Azure platform and integrating safety enhancements. Microsoft will gain a minority stake in G42, and its vice chair and president, Brad Smith, will join its board.
Anvilogic Raises $45 Million in Series C Funding
Anvilogic, based in San Alto, closed a $45 million Series C funding round led by Evolution Equity Partners, along with contributions from multiple returning investors.
They specialize in integrating security analytics across different data platforms without replacing existing security information and events (SIEM) systems, an important feature for enterprises shifting to cloud environments.
The funding will help expand Anvilogic’s generative AI capabilities within the security operations centre (SOC) lifecycle.
Rivos Raises $250 Million in Series A-3 Funding
Rivos, a startup focused on AI hardware, has raised $250 million in Series A-3 funding to develop RISC-V-based AI server chips for training LLMs.
The funding round, led by Matrix Capital Management and involving major investors like Intel Capital and MediaTek, will support the finalization of Rivos’ first silicon product and expand manufacturing operations.