- GenAI360 - Weekly AI News
- Posts
- Announcing Activeloop’s Scientific Discover
Announcing Activeloop’s Scientific Discover
Connecting Research Data to Intelligence for Faster Scientific Discovery
Davit Buniatyan
December 02, 2025
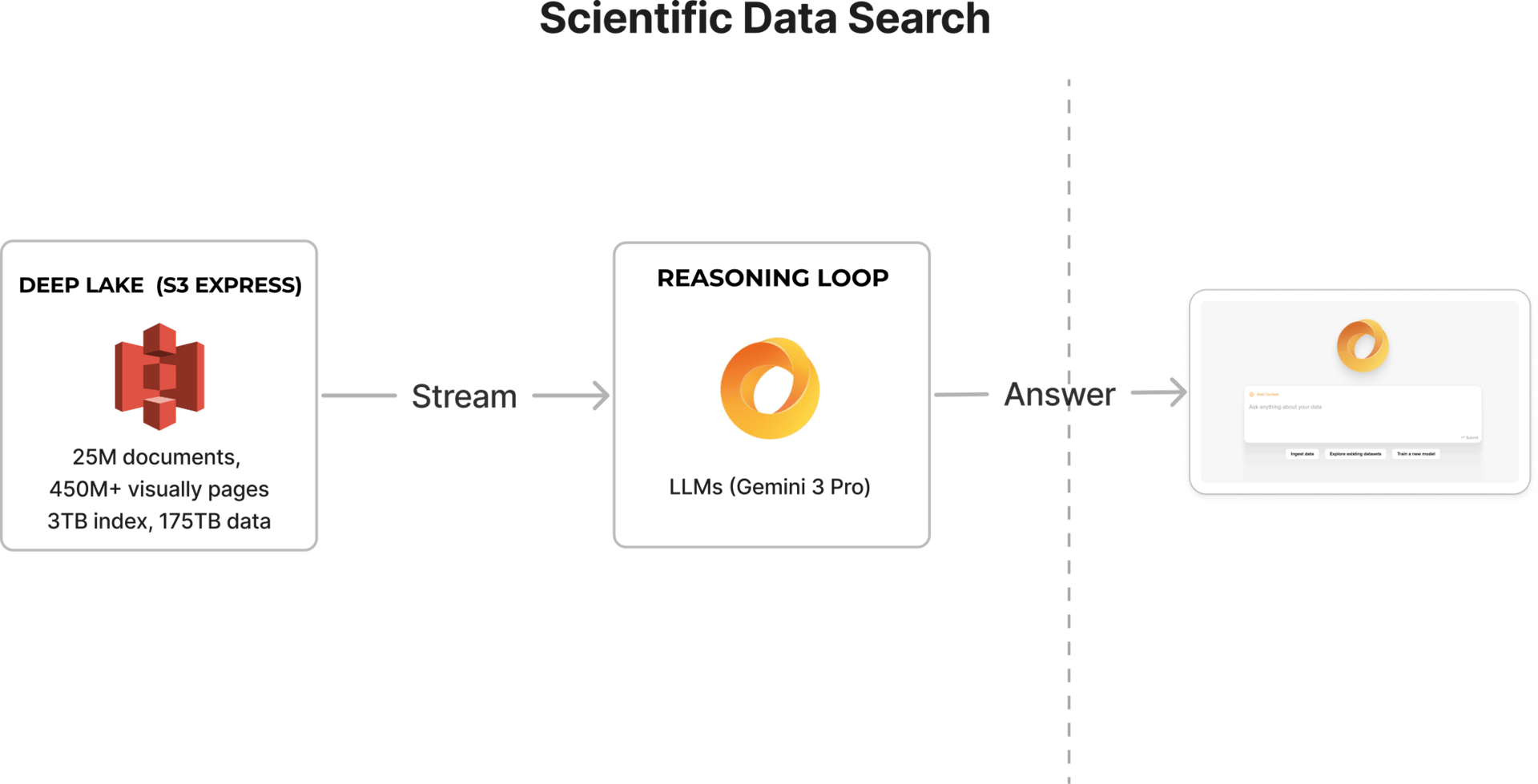
Today we are excited to release Activeloop’s Scientific Discover, an intelligence agent built on one of the largest datasets of indexed scientific research. Here are the details:
A fully indexed dataset of 25M open-access scientific papers: more than 450M pages of text, figures, charts, molecules, and tables (175TB+ total).
An open-source scientific intelligence agent built on this dataset, achieving 48% SOTA performance on Humanity’s Last Exam when paired with our tools and research index.
Researchers across biotech, life science, and academia tell us the same story.
“Our knowledge is everywhere, but our answers are nowhere.”
Scientific insight is buried inside PDFs, figures, screenshots, tables, and formats that machines cannot read. Teams lose weeks to extraction and cleanup instead of actual discovery.
This bottleneck slows breakthroughs in drug development, materials science, and every field that depends on research.
Activeloop’s Scientific Discover is a scientific data agent that reads and reasons across the entire scientific literature.
The US Needs to Unify All Scientific Data
The White House recently launched the Genesis Mission to unify all datasets for scientific discovery, recognizing that the current infrastructure cannot support the AI agents needed to cure diseases or discover new materials.
The Genesis Mission will build an integrated AI platform to harness Federal scientific datasets — the world’s largest collection of such datasets, developed over decades of Federal investments — to train scientific foundation models and create AI agents to test new hypotheses, automate research workflows, and accelerate scientific breakthroughs.
Fully indexed research data will accelerate scientific discovery through AI. Activeloop’s Scientific Discover takes a large step in this direction.
175TB of Scientific Research Data indexed on Deep Lake
We have successfully indexed 175TB of open-access scientific data, creating one of the world's largest AI-ready scientific datasets.
It is a fully structured, multimodal knowledge base powered by Deep Lake.
Traditional search engines see scientific papers as flat text mostly just titles and abstracts, often discarding the most critical data resorted within papers such as charts, molecular structures, and mathematical formulas.
By utilizing Deep Lake’s tensor-based storage, we have preserved this multimodal context, allowing our AI agents to "read" papers with the same visual and semantic understanding as a human researcher.
Scale: 25 million open-access papers comprising over 450+ million pages.
Multimodality: Images, tables, and graphs are indexed alongside text, preserving the relationships between distinct data types (e.g., a chemical structure image linked to its textual description).
Cutoff Date: March, 2025
Infrastructure: Built on Deep Lake’s "Index-on-the-Lake" technology, this dataset is stored efficiently on S3 Express, enabling sub-second retrieval of complex multimodal queries without the latency or cost of traditional vector databases.
This dataset serves as the foundational "brain" for the L1 Science Data Agent, ensuring it retrieves answers based on ground-truth scientific evidence rather than hallucination.
You run the queries over API or at chat.activeloop.ai/science
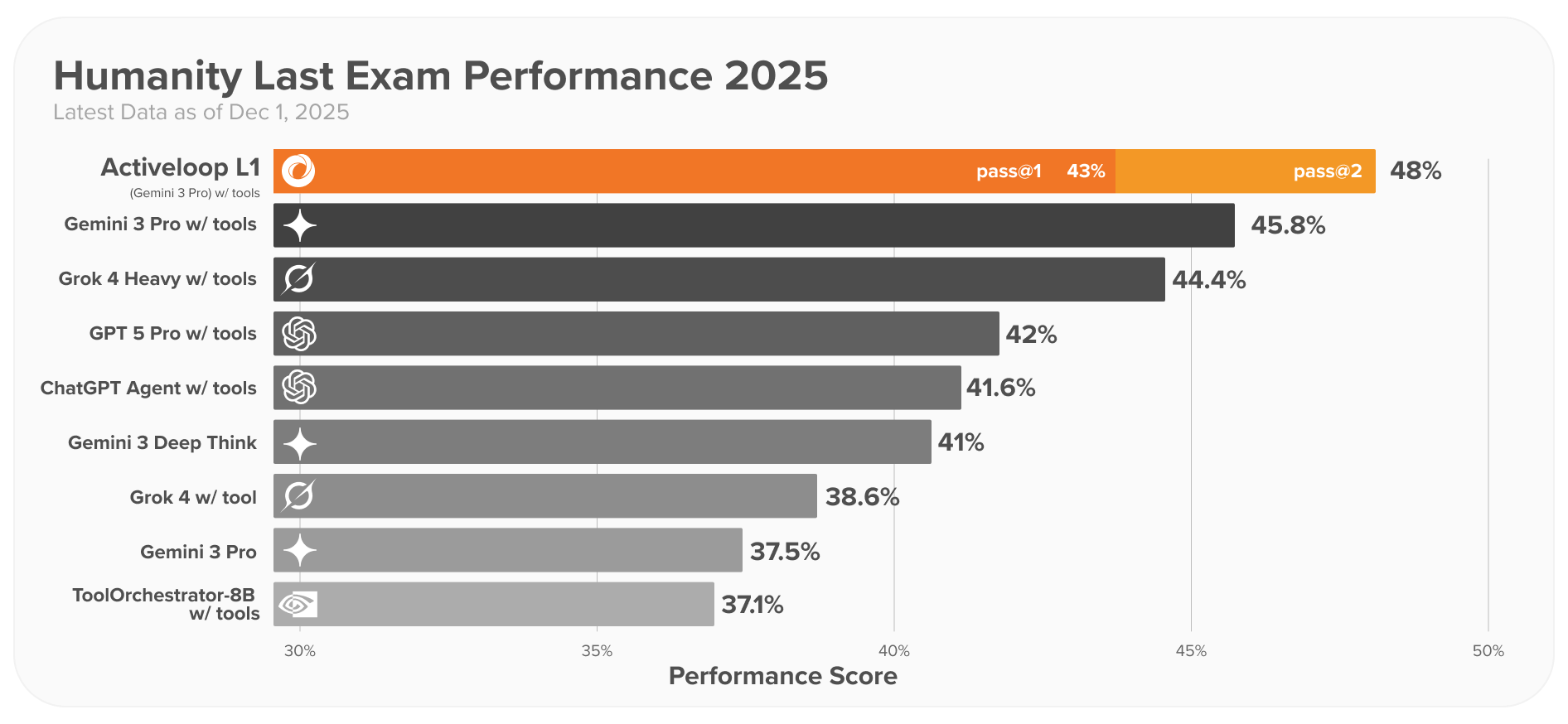
Humanity’s Last Exam
Equipping the data agent with 3 tools: Code Interpreter, Web Search and Scientific Search via Activeloop API we achieve state of the art results on HLE benchmark.
The agent achieves 43% accuracy in single pass, and with pass@2 48% attempting all 2500 queries including ones containing images or gifs. LLM cost per single iteration is under $1.
While not exactly the same, one might speculate that Deep Think, GPT5 Pro and Grok Heavy employ 8 parallel trajectories simultaneously and then aggregate the final result. It makes an approximately equivalent case to the pass@8 score.
To the most recent concerns of benchmark leakage especially with web search, we blocked access to the HuggingFace website. Furthermore, using LLMs we analyzed all executed traces to identify potential answer leaks. While 4.9% of answers suspected in leakage, only 0.2% where instances of tool usage (web search and scientific search).
We are open sourcing the full code to reproduce the benchmarks at http://github.com/activeloopai/hle
Activeloop L1: The Multimodal Scientific Agent
L1 is not a paper search engine. It is an AI researcher.
It understands:
text
charts
molecules
protein structures
formulas
experimental tables
clinical graphs
This is possible because L1 runs on the largest visually indexed scientific dataset ever created.
25 million papers. Over 175+ terabytes of fully indexed data.
Instant Scientific Intelligence
Ask a question like:
Which compounds show synergy with metformin for type 2 diabetes?
L1 reads molecular structures, clinical results, and experimental evidence in seconds.
No manual extraction. No stitching PDFs. No lost details.
Your team gets trusted, multimodal answers immediately.

Free Researchers to Do Real Discovery
By automating the extraction and integration of scientific data, L1 lets your researchers focus on:
identifying new drug targets
generating promising molecules
validating hypotheses
accelerating discovery cycles
Instead of spending their time cleaning data.
Key Applications for empowering the Genesis Mission
Activeloop L1’s main applications include:
Accelerating Biotechnology & Target Identification: Aligned with the mission to “cure diseases,” multimodal AI correlates diverse data such as gene expression, protein interactions, and clinical outcomes to pinpoint viable drug targets faster than humanly possible.
Critical Materials & Energy Dominance: Essential for “nuclear fission, fusion, and energy dominance.” The agent can explore vast chemical spaces to generate candidate structures for next-gen batteries or superalloys that satisfy conflicting properties like efficacy, safety, and thermal stability.
Semiconductors & Advanced Manufacturing: Supporting the race for “global technology dominance.” By indexing fabrication diagrams and material properties from millions of papers, the agent can suggest process improvements and novel material compositions for microelectronics.
Faster Science Discovery over API
Multimodal scientific research involves using AI to analyze and integrate data from multiple, diverse sources or modalities to gain a more holistic and accurate understanding of diseases and potential treatments.
Instead of relying on a text-based research paper, multimodal models combine information from all of them simultaneously. This approach mirrors how human experts synthesize knowledge from different sources.
You can try the agent today via our OpenAI-compliant API:
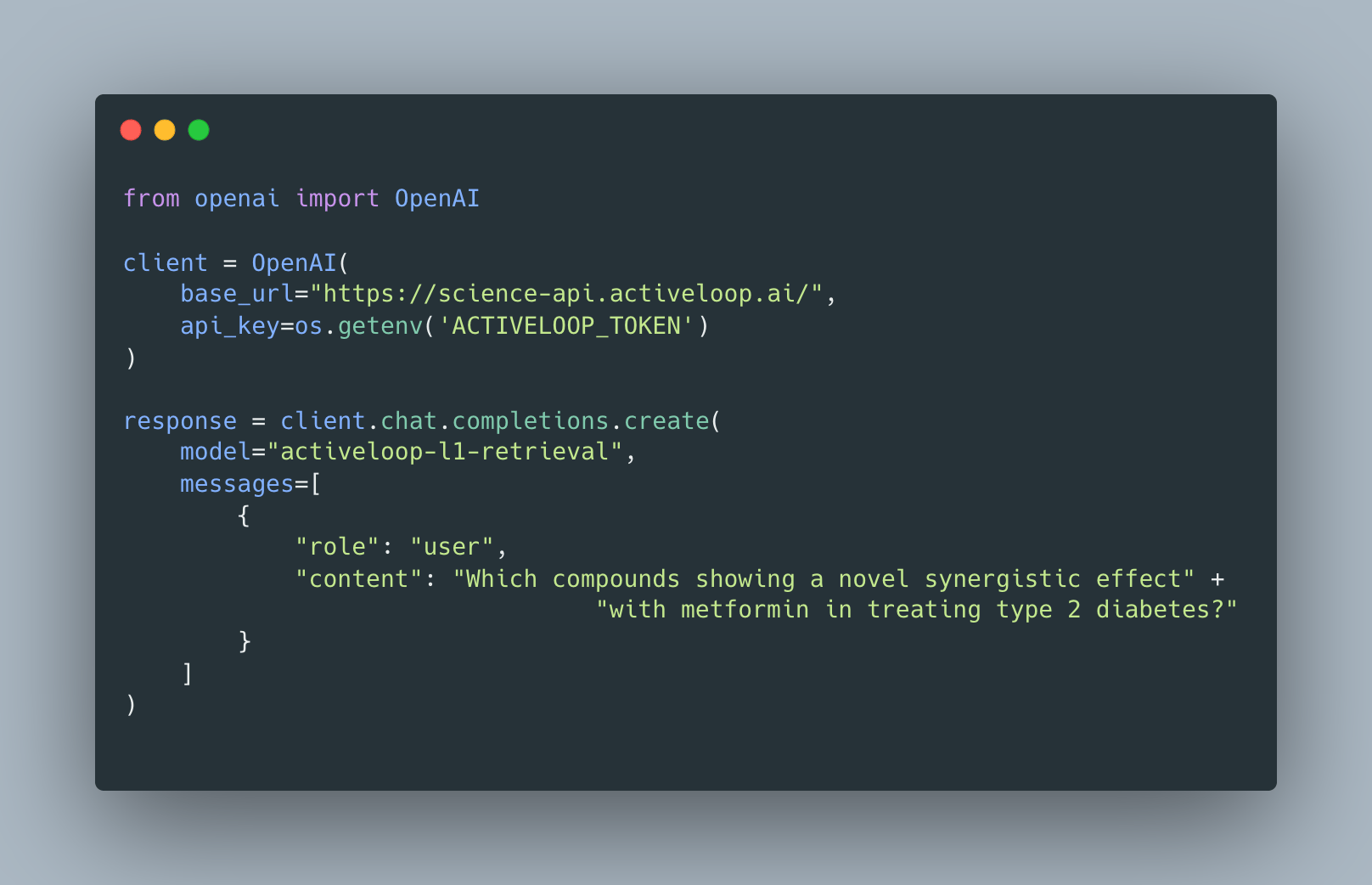
You can get an API KEY by signing up and subscribing at chat.activeloop.ai and learn more about the usage in docs.
Ready to Accelerate Discovery?
We are partnering with leading biotech and research teams to unlock the next generation of multimodal scientific innovation.
Try the Science Agent: chat.activeloop.ai/science